If you ask your manager, developers, clients or other stakeholders whether they think testing is important, you're very likely to get a resounding "yes, of course!". The question of why they believe it's important is usually more difficult for them to answer, though.
Testing is the process of evaluating a product by learning about it through experiencing, exploring, and experimenting, which includes to some degree: questioning, study, modelling, observation, inference, etc.
This definition highlights all of the aspects of why testing is important, with its focus on interacting with the product, engaging in learning and exploration, and running experiments to help find out if the software in front of us is the software we want for our clients.
This type of evaluation is important and also likely to be viewed as important by the business. Rather than providing test reports about passed and failed test cases, the kinds of valuable information provided by testing viewed in this way helps to counter the common impression of testing as being a costly nuisance.
The reality is that most stakeholders (and certainly customers) don't care about what testing we did or how we did it - but they probably care about what you learned while doing it that can be valuable in terms of deciding whether we want to proceed with giving the product to customers.
Learning to present testing outcomes in a language that helps consumers of the information to make good decisions is a real skill. Talking about risk (be that product, project, business or societal) based on what we’ve learned during testing, for example, might be exactly what a business stakeholder is looking for in terms of value from that testing effort.
Why testing is important
We want to find out if there are problems that might threaten the value of the software, so that they can be fixed before it reaches the customer.
We have a desire to know if the software we've built is the software we (and, by extension, our customers) wanted
So we need test approaches that focus on deliberately finding the important problems
It's more than just finding the easy or obvious bugs
The machines alone cannot provide us with this kind of knowledge (so we cannot rely on automation alone).
We cannot rely solely on the builders of the software for testing, as they lack the critical distance from what they've built to find deep and subtle problems with it.
Some clues that testing is not seen as important
How would teams/clients/organisations behave if software testing wasn't important to them? They would probably:
Try to cut the cost of it or find ways to justify not doing it all (especially with expensive humans).
Devalue the people doing testing by compensating them differently to other team members
Look upon testing work as a commodity that they can have performed by lowest common denominator staff (perhaps in a cheaper location).
Capitalize on their confirmation bias by appealing to the authority of the many articles and presentations claiming that "testing is dead".
Make sure that testing is seen as a separate function from the rest of development to enable their desire to remove it completely.
View testing as a necessary evil.
It's common to see these indications that software testing just isn't seen as important and, unfortunately, the software testing industry has traditionally done a poor job of articulating the value of testing and not being clear on what it is that good testing actually provides.
If you ask your manager, developers, clients or other stakeholders whether they think testing is important, you're very likely to get a resounding "yes, of course!". The question of why they believe it's important is usually more difficult for them to answer, though.
Everyone thinks they know what "testing" is. Like most things, though, there isn't a shared understanding of what testing really means across the IT industry.
Distinguishing "testing" and "checking" is a great way to help build this shared understanding when we're talking about this critical part of the software development process.
Common perceptions of "testing"
A commonly held view is that the purpose of testing is to detect non-conformances between a product and its specifications, so that they may be resolved. Specifications may exist on several levels and the concept of "verification" means checking a component against its immediate specification.
"Testing" is often conflated with "finding bugs" and we all know how easy it is to find bugs in the software we use every day:
There's a reason that many people think testing is easy, due to an asymmetry. No one ever fired up a computer and stumbled into creating a slick UI or a sophisticated algorithm, but people stumble into bugs every day. Finding bugs is easy, they think. So testing must be easy.
- Michael Bolton
Testing and checking
Let's dive into the definitions of testing and checking from James Bach and Michael Bolton (in Testing and Checking Refined):
Testing is the process of evaluating a product by learning about it through experiencing, exploring, and experimenting, which includes to some degree: questioning, study, modeling, observation, inference, etc.
Checking is the process of making evaluations by applying algorithmic decision rules to specific observations of a product.
Many people view "testing" as what is defined above as "checking". While checking particular facts about the product is important (e.g. checking that a story meets its acceptance criteria), there is much more to good testing than just checking "known knowns" like this. (Notice how checking sounds like work that is amenable to automation).
As a good tester, we are tasked with evaluating a product by learning about it through exploration, experimentation, observation and inference. This requires us to adopt a curious, imaginative and critical thinking mindset, while we constantly make decisions about what’s interesting to investigate further and evaluate the opportunity cost of doing so. We look for inconsistencies by referring to descriptions of the product, claims about it and within the product itself. These are not easy things to do.
We study the product and build models of it to help us make conjectures and design useful experiments. We perform risk analysis, taking into account many different factors to generate a wealth of test ideas. This modelling and risk analysis work is far from easy.
We ask questions and provide information to help our stakeholders understand the product we've built so that they can decide if it’s the product they wanted. We identify important problems and inform our stakeholders about them – and this is information they sometimes don’t want to hear. Revealing problems (or what might be problems) in an environment generally focused on proving we built the right thing is not easy and requires emotional intelligence & great communication skills.
We choose, configure and use tools to help us with our work and to question the product in ways we’re incapable of (or inept at) as humans without the assistance of tools. We might also write some code (e.g. code developed specifically for the purpose of exercising other code or implementing algorithmic decision rules against specific observations of the product, “checks”), as well as working closely with developers to help them improve their own test code. Using tooling and test code appropriately is not easy.
This heady mix of aspects of art, science, sociology, psychology and more – requiring skills in technology, communication, experiment design, modelling, risk analysis, tooling and more – makes it clear why good software testing is hard to do!
Testing is a learning process and provides valuable information about the product
Testing is an information service provider, helping stakeholders to make informed risk-based decisions about the software. The information produced by testing relies on learning, evaluation and experimentation, human skills that are not replaceable by machines (even the most sophisticated AI lacks the social context to be good at these kinds of activities).
You might want to check out Michael Bolton’s "Testing Rap" (from which some of the above was inspired) as a fun way to remind people about all the awesome things involved in really good testing!
Video: Michael Bolton's Hamilton Inspired Rap From TestBash Manchester (2 min)
Everyone thinks they know what "testing" is. Like most things, though, there isn't a shared understanding of what testing really means across the IT industry.
Distinguishing "testing" and "checking" is a great way to help build this shared understanding when we're talking about this critical part of the software development process.
Without a good understanding of testing and its limitations, it's easy for clients and customers to believe that we "test everything" - but there's a problem with this belief:
Complete (or 100% or exhaustive) testing is impossible.
Figure: Bill Lumbergh might well ask someone to "test everything" (from the movie Office Space)
Why is it impossible?
Figure: Don't take on impossible missions!
Complete testing is impossible for several reasons:
We can’t test all the inputs to the program.
We can’t test all the combinations of inputs to the program.
We can’t test all the paths through the program.
We can’t test for all of the other potential failures, such as those caused by:
User interface design
errors and other usability problems
Incomplete requirements analyses
Malfunctioning hardware
Humans making mistakes when using the software
Hardware/software compatibility issues
Timing issues, etc.
For non-trivial programs, complete testing is impossible because the population of possible tests is infinite. So, you can’t have complete coverage - no matter how many tests you run, only partial coverage can be achieved.
What about "100% coverage"?
You might think that achieving "100% coverage" is the same as complete testing, especially if you listen to the claims of coverage tool vendors. 100% of what, though?
Some people might say that "100% coverage" could refer to lines of code, or branches within the code or the conditions associated with the branches. Saying "100% of the lines (or branches, or conditions) in the program were executed" doesn’t tell us anything about whether those lines were good or bad, useful or useless.
"100% code coverage" doesn’t tell us anything about what the programmers intended, what the user desired or what the tester observed. It says nothing about the tester's engagement with the testing; whether the tester was asleep or awake. It ignores how the tester recognized - or failed to recognize - bugs and other problems that were encountered during the testing.
Code coverage is usually described in terms of the code that we’ve written. Yet every program we write interacts with some platform that might include third-party libraries, browsers, plug-ins, operating systems, file systems, firmware, etc. Our code might interact with our own libraries that we haven’t instrumented this time. So "code coverage" always refers to some code in the system, but not all the code in the system.
Testing is an open investigation. 100% coverage of a particular factor may be possible, but that requires a model so constrained that we leave out practically everything else that might be important. Relying on "100% coverage" means that we will miss significant classes of bugs.
We can’t do complete testing, so what can we do?
Since complete testing is impossible, choosing the tests to perform is essentially a sampling problem. Adopting approaches such as risk-based testing are important in making good sampling decisions.
The focus should be on doing "good enough testing". You can say you’re done when you have a testing story adequately covering the risks agreed with your stakeholders and you can make the case that additional tests will probably not significantly change your story. Depending on the situation, this might require months of testing, sometimes only hours.
Figure: Aim for "good enough" testing over complete testing
Without a good understanding of testing and its limitations, it's easy for clients and customers to believe that we "test everything" - but there's a problem with this belief:
Complete (or 100% or exhaustive) testing is impossible.
There is a common misconception that you can automate all the testing.
While there can be great value in using automation in testing, human capabilities are still required for the key testing skills such as evaluation, experimentation, exploration, etc.
Figure: Bill Lumbergh might well ask someone to "automate all the testing" (from the movie Office Space)
Remember the difference between testing and checking
Testing is the process of evaluating a product by learning about it through experiencing, exploring, and experimenting. This includes questioning, study, modeling, observation, inference, etc.
Checking is the process of making evaluations by applying algorithmic decision rules to specific observations of a product.
Looking at these definitions, testing is clearly a deeply human activity. Skills such as learning, exploring, questioning and inferring are not well suited to machines (even with the very best AI/ML). Humans may or may not use tools or other automation while exercising these skills, but that doesn’t mean that the performance of testing is itself "automated".
Checking is a valuable component of our overall testing effort and, by this definition, lends itself to be automated. But the binary evaluations (pass/fail) from such checks only form a small part of the testing story.
There are many aspects of product quality that are not amenable to such black and white evaluation.
Thinking about checks, there's a lot that goes into them apart from the actual execution (by a machine or otherwise). For instance, someone...
Decided we needed a check (risk analysis)
Designed the check
Implemented the check (coding)
Decided what to observe and how to observe it, and
Evaluated the results from executing the check
These aspects of the check are testing activities and, importantly, they're not aspects that can be given over to a machine (i.e. be automated). There is significant testing skill required in the design, implementation and analysis of the check and its results - the execution (the automated part) is really the easy part.
A machine producing a bit is not doing the testing; the machine, by performing checks, is accelerating and extending our capacity to perform some action that happens as part of the testing that we humans do. The machinery is invaluable, but it’s important not to be dazzled by it. Instead, pay attention to the purpose that it helps us to fulfill, and to developing the skills required to use tools wisely and effectively.
--- Michael Bolton
Countering suggestions to "automate all the testing"
There is often value to be gained by automating checks and leveraging automation to assist and extend humans in their testing efforts, but the real testing lies with the humans – and always will.
The next time someone suggests that you "automate all the testing", remind them this means you will need to:
"Automate the evaluation
and learning
and exploration
and experimentation
and modeling
and studying of the specs
and observation of the product
and inference-drawing
and questioning
and risk assessment
and prioritization
and coverage analysis
and pattern recognition
and decision making
and design of the test lab
and preparation of the test lab
and sensemaking
and test code development
and tool selection
and recruiting of helpers
and making test notes
and preparing simulations
and bug advocacy
and triage
and relationship building
and analyzing platform dependencies
and product configuration
and application of oracles
and spontaneous playful interaction with the product
and discovery of new information
and preparation of reports for management
and recording of problems
and investigation of problems
and working out puzzling situations
and building the test team
and analyzing competitors
and resolving conflicting information
and benchmarking..."
(Kudos to Michael Bolton again for the above list)
Check out Huib Schoots and Paul Holland talking about "Automation Addiction" in their Romanian Testing Conference 2022 keynote. They explain why testing can't be completely automated as well as discussing some common misconceptions and problems around automation.
Video: Huib Schoots & Paul Holland - Automation Addiction (52 min)
There is a common misconception that you can automate all the testing.
While there can be great value in using automation in testing, human capabilities are still required for the key testing skills such as evaluation, experimentation, exploration, etc.
"Critical distance" refers to the difference between one perspective and another, the difference between two ways of thinking about the same thing.
You know how easy it is for someone else to spot things - both good and bad - about your work that you haven’t noticed. You're "too close" to the work to be truly critical of it.
Developers naturally have a builder mindset focused on success, while testers are likely to have a more skeptical, critical-thinking mindset.
The critical distance between the mindset of a developer and a tester is important for excellent testing.
Figure: Taking advantage of critical distance reduces the chances of being fooled
Diverse teams foster increased critical distance
Diversity in testing is an idea that has to be taken seriously, because it's essential to have different perspectives to foster critical distance between mindsets.
The more we're all alike, the greater the chance that we'll be fooled by missing something important.
Diversity is a powerful heuristic for addressing that problem, not only diversity of genders and identities, but also of cultures, ethnicities, experiences, temperaments, skills, approaches, etc.
Developer testing
While developers are building their code, their mental models of their work are already developed and so creating checks for specific factors and functions (e.g. in unit tests) is straightforward.
This means that shallow testing of simple things can easily be performed by the developer. "Shallow" here refers to problems that are near the surface, close to the coal face of where the developer is working.
Such shallow checking and testing is highly valuable; it's good to identify problems when they're less hard to see. But we must also remain alert to the fact that deeper, subtler, worse problems won’t all yield to this kind of shallow testing.
Developers are mostly envisioning success. They enact the essential, fundamentally optimistic task of solving problems for people, which requires believing that those problems can be solved, and building those solutions. Developers act as agents between the world of humans and the world of machines.
Testing more deeply
While shallow testing is plausible at a close critical distance, deeper testing tends to require or create more distance from the builder’s mindset.
Testers are always responding to something that has been created by someone else. This is actually a good thing: the tester must develop an independent mental model of the product that was not developed in parallel with the building of it. In doing so, they create valuable critical distance.
Figure: Testers bring skepticism to what we've built
Testers act as agents between the world of technological solutions and the world of skepticism and doubt. Testers must remain professionally and responsibly uncertain that there are no problems, even when everyone around us is sure there are no problems.
To find those deeper problems means challenging the product with complex testing: investigating for problems, not just confirming that everything seems OK.
Critical distance is essential for deeper testing; to find hidden, subtle, rare, intermittent or emergent bugs; to probe the product to learn about problems unanticipated by the builders.
Cultivate critical distance
Testing benefits from diverse perspectives which help cultivate critical distance, increasing the chances of identifying important problems in what we've built.
Tip: If a developer is acting as the tester for another developer's work (e.g. performing a "Test Please"), they still benefit from the critical distance of not having built what they're testing.
"Critical distance" refers to the difference between one perspective and another, the difference between two ways of thinking about the same thing.
You know how easy it is for someone else to spot things - both good and bad - about your work that you haven’t noticed. You're "too close" to the work to be truly critical of it.
Developers naturally have a builder mindset focused on success, while testers are likely to have a more skeptical, critical-thinking mindset.
The critical distance between the mindset of a developer and a tester is important for excellent testing.
We know that complete testing is impossible so how do we decide which finite set of tests to perform out of the infinite cloud of possible tests for a story, feature or release?
This problem can seem overwhelming, but focusing on risk is a good approach so let's look at risk-based testing.
What is risk-based testing?
Think of risk as the possibility of a negative or undesirable event or outcome; a risk is a problem that might happen.
Quality risk is the possibility that the software might fail to deliver one or more of its key quality attributes, e.g. reliability, usability, performance, capability, etc.
Risk-based testing uses an analysis of quality risks to prioritize tests and allocate testing effort
How does a risk-based approach help with test planning?
Risk-based testing delivers the following benefits:
Find the scariest problems first
Running the tests in risk order gives the highest likelihood of discovering problems in severity order, so we find the most important problems first.
Pick the right tests out of the infinite cloud of possible tests
Allocating test effort based on risk is the most efficient way to minimize the residual quality risk upon release.
Release when risk of delay balances risk of dissatisfaction
Measuring test results based on risk allows the organisation to know the residual level of quality risk during test execution and to make smarter release decisions.
Give up tests you worry about the least
If the schedule requires it, dropping tests in reverse risk order reduces the test execution period with the least possible increase in quality risk.
These benefits allow testing to be more efficient and targeted, especially in time and/or resource constrained situations (which is pretty much always the case!).
Putting risk-based testing into practice
The concept of risk-based testing is straightforward and you can put it into practice easily - by starting simple!
Identify risks
Identifying quality risks is the first step in making use of a risk-based approach to testing.
Risk analysis workshops are a good way to involve different stakeholders in this process and you can drive these workshops in at least a couple of different ways:
Begin with details about the situation and identify risks associated with them. With this approach, you study the software and repeatedly ask yourself "What could go wrong here?"
Begin with a set of potential risks and match them to the details of the situation. With this approach, you consult a predefined list of risks and determine whether they apply here and now. These risk lists could be in the form of a set of Quality Criteria categories, generic risk lists or risk catalogues.
Tip: Start with a simple approach to your risk analysis, then become more advanced as your teams become more familiar with the risk-based approach
Tip: Try to gather diverse opinions about risk. Technical folks will likely identify different types of risk to business stakeholders, while testers will bring yet another perspective.
Order the risks
After identifying quality risks, the next job is to order them.
Consider the likelihood and impact of each risk as a simple way to perform this ordering exercise. So a risk that seems quite likely to eventuate and would result in significant impact to all of your users would rank higher than one that is less likely to happen or would only cause problems for a small number of users.
Prioritize testing based on the risks
Formulate your test plans to address the highest risks first, to ensure that you're covering the riskiest stuff first and increasing the chances of finding the most important problems earlier rather than later.
We know that complete testing is impossible so how do we decide which finite set of tests to perform out of the infinite cloud of possible tests for a story, feature or release?
This problem can seem overwhelming, but focusing on risk is a good approach so let's look at risk-based testing.
In a Scrum team, every member of the team has some responsibility for the quality of the deliverables of the team.
If you have a dedicated tester embedded in the Scrum team, they are not solely responsible for performing all of the types of testing required to help build a quality deliverable.
Figure: The whole team needs to take on responsibility to achieve great quality (source: infamous-labyrinth.flywheelsites.com/about/microsoft-awards)
The idea of adopting a "whole team approach to quality" is to build quality into the software rather than trying to test the problems out of it at the end.
Figure: Wise words from Deming on achieving higher quality
So, what is "quality"?
There are many definitions of "quality". A simple but very useful definition is:
Quality is value to some person(s) who matter(s)
- Jerry Weinberg (with changes by Michael Bolton & James Bach)
This definition highlights the fact that quality is a relationship between the user and the product - it's not the product itself, nor an element of the product. The user's perception of value is also subjective.
Acknowledging the subjective nature of quality is important, so that we don't fall into the trap of trying to measure it. Quality is more amenable to assessment than it is to measurement.
Testing ≠ quality
This might be hard to swallow but, just like weighing yourself doesn't cause you to lose weight:
Testing does not improve quality
Testing provides valuable information about the software - and the processes involved in creating it, building it and deploying it - and it is only by acting on this information that quality may be improved.
The whole team approach
Every member of the Scrum team has their part to play in building quality into their deliverables. There are different kinds of testing activities that rely on different skills found across the various people making up a diverse Scrum team.
This mission statement from Atlassian is a good expression of the aim of modern testing and quality management:
"We want to help ship awesome software, not just prevent poor software from being released"
Atlassian Quality Engineering group mission (from job advertisement, April 2020)
The idea is not to rely on someone with the role/title of "tester" to do all of the testing work!
Some examples follow of how the different roles in a Scrum team contribute to quality.
Developer
By writing unit tests, developers enable fast feedback on code changes so that low-level problems can be identified quickly and resolved before impacting customers.
Code reviews can help to prevent problems from even being committed to the source code repository and adhering to coding standards helps to maintain good quality at the code level.
Scrum Master
With their key responsibility to remove blockages, the Scrum Master actively contributes to quality by ensuring that development can continue unimpeded. Any context-switching resulting from blockers increases the risk of problems being introduced.
Keeping the Scrum board in an accurate state also assists from a quality perspective, so that the developers are working on the right things at the right time, building the highest value software for our customers.
Product Owner
The availability of a Product Owner to provide quick and accurate feedback and answers to team members' questions is critical to building a quality product. With their focus on priorities and defining the stories to implement, the Product Owner helps to build the right thing for our customers with quality in mind.
Tips for building quality in
Think "testing", not "tester"
Testing is an activity and can potentially be performed by different members of a Scrum team, e.g. developers might write unit tests, testers might perform exploratory testing.
By thinking in terms of the activity, "testing", rather than a person or role, "tester", it becomes more obvious that the responsibility for testing spreads across the whole Scrum team.
Turn testing problems into problems for the whole Scrum team to address
When faced with a testing problem in the team, make it the whole team's responsibility to find solutions. Even if you have a tester embedded in the Scrum team, they might not be the best person to solve a testing problem.
For example, suppose the software has poor testability that could be enhanced by adding hooks, APIs or logging. Assigning the work to add these testability features to a developer is probably more appropriate than giving it to the tester.
Focus on preventing misunderstandings about feature behaviour as well as preventing defects in the code
Good practices such as code reviews and static code analysis can help to keep the codebase in a high-quality state. But having great code doesn't mean you end up with a great product!
Focusing solely on "building it right" is only half the story, so actively take steps to ensure you're "building the right thing". Working towards a shared understanding of what it is you're building (and why) can help to prevent costly rework and dissatisfied customers.
Use diverse perspectives from the whole team to gain a better understanding of risk
Building an understanding of the risks involved in delivering a feature is not easy, but it's made easier by utilizing diverse perspectives.
Testers are generally skilled in risk analysis and so can be highly valuable in this process. But developers are likely to be great at thinking about technical risks and business stakeholders are awesome at identifying business risks, so make use of a diverse group to more fully understand risk.
This information is critical in formulating testing strategies to mitigate the identified risks. Remember, "Risk is what's left over after you think you've thought of everything" (Carl Richards, The Behavior Gap).
Perform diverse testing activities
Examples:
Having conversations to build shared understanding
Asking questions to test ideas and assumptions
Automating tests
Performing exploratory testing
Testing for quality attributes such as performance, reliability and security
Learning from production usage
Use whole team retros and small experiments to continually improve testing and quality and find out what works in your context.
Deliberately adding an item for testing and quality onto your Sprint Retro agenda can be helpful as a reminder.
The Agile Testing Manifesto
Many of the mindset shifts required to think in terms of a whole team approach to quality are nicely encapsulated in the Agile Testing Manifesto (which is deliberately phrased in a similar way to the Agile Manifesto).
Figure: The Agile Testing Manifesto, by Karen Greaves & Samantha Laing
Some anti-patterns
There are some common anti-patterns that indicate a Scrum team is not taking a whole team approach to quality.
The "testing phase"
If you still refer to a "testing phase", it's likely that testing is not seen as an activity but rather a stage or phase.
Testing should be a continuous process, working alongside development and performing appropriate types of testing at the right time throughout story development.
Asking "how did QA miss this bug?"
If a bug finds its way into production and is reported by a customer, asking this question implies that only testers are responsible for testing, rather than the whole team. It's worth remembering that testers don't put the bugs into the code!
A more productive question to ask is "How can the whole team make changes - to its development, testing and deployment practices - to avoid similar issues leaking into production in the future?"
Testing a Sprint behind development
If stories are considered "finished" when the code is done but testing still needs to be performed in the next Sprint, then the team is still viewing coding and testing as separate, rather than concurrent, activities.
This problem is most commonly seen for automated tests, where the story is coded and tested (by humans) in the Sprint but the effort to create good automated tests is deferred to the next (or another future) Sprint. This accumulates technical debt and adds untested code into the codebase, so is not a good practice.
Remember that all planned testing should be completed for a story as part of its Definition of Done, meaning it needs to be done in the same Sprint as all the other work for the story.
Focusing on meeting the Sprint commitment over meeting the DoD
While the goal is to meet the Sprint commitment, this goal shouldn't be achieved at the expense of quality. The DoD is there to help achieve a consistent, desired level of quality by detailing all of the work to be done before a story can be considered complete.
Calling a story done in order to meet the Sprint commitment and then fixing known defects later is a false economy - this practice leads to the deliberate accumulation of technical debt, which costs more to pay down later.
If nothing else, calling a story "done" when it's not done is just cheating - and cheats always get found out, eventually!
In a Scrum team, every member of the team has some responsibility for the quality of the deliverables of the team.
If you have a dedicated tester embedded in the Scrum team, they are not solely responsible for performing all of the types of testing required to help build a quality deliverable.
We know that complete testing is impossible, so we need ways to help us decide when to stop testing... aka when we've done "enough" testing.
"Genius sometimes consists of knowing when to stop."
— Charles de Gaulle
Risk-based testing
Since complete testing is impossible, choosing the tests to perform is essentially a sampling problem. Adopting approaches such as risk-based testing is important in making good sampling decisions.
The focus should be on doing "good enough testing". You can say you're done when you have a testing story adequately covering the risks agreed with your stakeholders and you can make the case that additional tests will probably not significantly change your story. Depending on the situation, this might require months of testing, sometimes only hours.
Stopping heuristics
There are other ways to decide when to stop testing.
Heuristics are quick, inexpensive ways of solving a problem or making a decision.
Heuristics are fallible: they might work and they might not work.
The Time’s Up! Heuristic. This is a common situation, we stop testing simply because the time allocated for testing has run out.
The Piñata Heuristic. We stop testing when we see the first sufficiently dramatic problem (named because we stop whacking the software when the candy starts falling out).
The Dead Horse Heuristic. The program is too buggy to make further testing worthwhile. We know that there will be so much rework that any more testing will be invalidated by the changes.
The Mission Accomplished Heuristic. We stop testing when we have answered all of the questions that we set out to answer.
The Mission Revoked Heuristic. Our client has told us, "Please stop testing now." The budget might have run out or the project has been cancelled.
The I Feel Stuck! Heuristic. For whatever reason, we stop because we perceive there’s something blocking us. Maybe we don’t have the information we need or there's a blocking bug, such that we can’t get to the area of the product that we want to test, for example.
The Pause That Refreshes Heuristic. Instead of stopping testing, we suspend it for a while, e.g. because we're tired or distracted, or need to do more research.
The Flatline Heuristic. No matter what we do, we’re getting the same result, e.g. the software has crashed or has become unresponsive in some way.
The Customary Conclusion Heuristic. We stop testing when we usually stop testing. There’s a protocol in place for a certain number of test ideas, or test cases, or test cycles or variation, such that there’s a certain amount of testing work that we do and we stop when that’s done.
The No More Interesting Questions Heuristic. At this point, we’ve decided that no questions have answers sufficiently valuable to justify the cost of continuing to test, so we’re done.
The Avoidance/Indifference Heuristic. Sometimes people don’t care about more information or the business reasons for releasing are so compelling that no problem that we can imagine would stop shipment, so no new test result would matter.
The Mission Rejected Heuristic. We stop testing when we perceive a problem for some person - in particular, an ethical issue - that prevents us from continuing work, e.g. would you continue a test if it involved providing fake test results or lying?
We know that complete testing is impossible, so we need ways to help us decide when to stop testing... aka when we've done "enough" testing.
"Genius sometimes consists of knowing when to stop."
— Charles de Gaulle
Exploratory testing is an approach to testing that fits very well into agile teams and maximises the time the tester spends interacting with the software in search of problems that threaten the value of the software.
Exploratory testing is often confused with random ad hoc approaches, but it has structure and is a credible and efficient way to approach testing.
Let's dig deeper, look into why this approach is so important, and dispel some of the myths around this testing approach.
Definition
James Bach and Michael Bolton define Exploratory Testing (ET) as follows:
Testing is the process of evaluating a product by learning about it through exploration and experimentation, which includes: questioning, study, modeling, observation and inference, output checking, etc.
Other definitions of exploratory testing focus on the idea of learning, test design and test execution being concurrent (rather than sequential) activities. Exploratory Testing is an approach to software testing that emphasizes the personal freedom and responsibility of each tester to continually optimize the value of their work.
Why is exploratory testing so important?
Exploratory testing affords testers the opportunity to use their skills and experience to unearth deeper problems in the software under test.
Figure: Explore to learn about the "unknown unknowns"
Rather than constraining the testing to "known knowns" (from requirements, user stories, etc.), exploration allows different kinds of risks to be investigated and "unknown unknowns" to be revealed.
It is often the case that the most serious problems in the software reside in these areas that were not clearly specified or understood before testing started.
How does exploratory testing compare with scripted approaches to testing?
No matter how you currently perform testing within your team, your approach will belong somewhere on a continuum from a purely scripted form of testing to a fully exploratory form of testing:
Figure: The continuum from pure scripted to full exploratory testing
A purely scripted approach is favoured by the "factory" school of testing, where scripts are created in advance based on the requirements documentation and are then executed against the software later, potentially by someone different than the author. The idea here is that everything can be known in advance and coverage is known and guaranteed via the prescriptive steps in the test case. This approach is obviously very rigid and does not account well for when unexpected things happen during execution of the script or for the fact that different testers will execute the exact same steps differently (breaking the so-called benefit of "reproducibility" in purely scripted testing).
Scripts can be made more vague, by specifying the tests in a step-by-step fashion but leaving out any detail that does not absolutely need to be specified (one way to do this is to omit the "Expected Results" for each step, thereby making the tester think more about whether what they see is what they realistically expect to see). You can then consider a more improvised approach in which you still have scripts, but actively encourage deviation from them.
A middle ground is fragmentary test cases, where you specify tests as single sentences or phrases, eliminating the step-by-step detail and omitting prescriptive expected results. Charters are a key concept in managing exploratory testing and they basically specify a mission for a timeboxed period of testing (say, 90 minutes), with the mission being expressed in two sentences or less - enough direction to focus the tester on their mission, but leaving enough freedom for the tester to exercise their judgment and skill.
Another exploratory approach is to assign each tester a role to test a certain part of the product, then leave the rest up to them. The use of heuristics becomes more critical and valuable as you approach this exploratory end of the continuum, to help the tester come up with test ideas during their freestyle exploratory testing.
Some exploratory testing myths
Exploratory Testing is just a fancy name for ad hoc testing
Random "keyboard bashing" and testing without any real direction or purpose is ad hoc testing, it is not exploratory testing. Remember that in true exploratory testing, the tester is learning, designing and executing tests concurrently - they are not just randomly doing things without thinking about what they are doing, what particular kind of issues they are looking for, and what test ideas they need to use to look for those kind of issues. In fact, ET is systematic, not random.
Exploratory Testing is too unstructured to be taken seriously
The structure of ET comes from many sources:
Test design heuristics
Chartering
Timeboxing
Perceived product risks
The nature of specific tests
The structure of the product being tested
The process of learning the product
Development activities
Constraints and resources afforded by the project
The skills, talents and interests of the tester
The overall mission of testing
One structure, however, tends to dominate all the others - the Testing Story. Exploratory testers construct a compelling story of their testing and it is this story that gives ET a backbone. To test is to compose, edit, narrate and justify three stories:
A story about the status of the product
About how it failed and how it might fail
In ways that matter to your various clients
A story about how you tested it
How you configured, operated and observed it
About what you haven't tested, yet
And won't test, at all
A story about how good that testing was
What the risks and costs of testing are
How testable (or not) the product is
What you need and what you recommend
The testing story can be recorded in artifacts called session sheets but it should be obvious that the richness of this storytelling provides stakeholders with much more valuable information about your testing than, say, a pass/fail result on a test case.
Exploratory Testing doesn't work unless you have highly experienced testers
It is a misconception that an exploratory approach to testing is best reserved for highly experienced testers. Less experienced (even less skilled) testers can still become great exploratory testers if their mindset is right for it - a desire to continually improve and learn is required, as is a genuine interest in providing value to their projects by providing testing-related information in a way that stakeholders can act upon.
Exploratory Testing lacks the rigour to be used in regulated environments
The different approach to documenting the test effort in exploratory testing is often claimed to lack the rigour required by auditors for teams working in regulated environments, such as finance or healthcare. This is simply untrue and there are now many well-documented case studies of the use of ET within regulated industries. Auditors are generally interested in answering two questions: "can you show me what you're supposed to do?" and "can you show me the evidence of what you actually do?". They are less interested in the form that the evidence takes. For example, formal test scripts actually provide less evidence of what was actually tested than a well-written testing story from a session of exploratory testing.
Josh Gibbs has written on this topic in his article Exploratory Testing in a Regulated Environment and James Christie is another excellent advocate for the use of ET within regulated environments, as he spent many years as an auditor himself and knows the kinds of evidence they seek in order to complete their audits. Griffin Jones gave an excellent presentation on this topic at the CAST 2013 conference, What is Good Evidence.
Exploratory testing is an approach to testing that fits very well into agile teams and maximises the time the tester spends interacting with the software in search of problems that threaten the value of the software.
Exploratory testing is often confused with random ad hoc approaches, but it has structure and is a credible and efficient way to approach testing.
Let's dig deeper, look into why this approach is so important, and dispel some of the myths around this testing approach.
A big suite of various levels of automated tests can be a great way of quickly identifying problems introduced into the codebase.
As your application changes and the number of automated tests increases over time, though, it becomes more likely that some of them will fail.
It's important to know how to handle these failures appropriately.
Figure: How not to handle automated test failures (Sander van der Wel from Netherlands, CC BY-SA 2.0, via Wikimedia Commons)
Some anti-patterns in handling automated test failures
When automated tests fail due to a genuine problem in the software, this is a good thing! You should thank them and address the problem asap.
But what about test failures due to other reasons? Let's look at some common anti-patterns for dealing with such failures.
Tolerate the failures
Some "reasons" for tolerating test failures include:
There are some "flaky" tests and they'll probably pass if we just re-run them - read this Twitter thread from Michael Bolton on so-called "flaky tests"
Only a few tests are failing (out of thousands), so it's not a big deal!
It's always the same tests that fail, so we know everything is really OK even though the build is not "green"
We haven't got time to fix the tests right now, we'll come back and fix them later
Tolerating test failures quickly erodes the trust in the results of the tests, to the point where the results are ignored and so they become pointless to run. This is a significant waste of your investment in building automated tests.
You need anything other than a "green build" to be a problem that the whole team takes seriously. This requires your automated tests to be reliable and stable, so that they only fail when they've identified a problem in the software.
Tip: It's better to have fewer, more reliable tests than more, unreliable ones (since the results of these unreliable tests don't tell you anything definitive about the state of the software under test).
"Skip" the failing tests
It might be tempting to deliberately skip the failing tests to get back to a "green build" state, with the intention of fixing them later.
The first problem with this is those failing tests that you're choosing to skip might actually be tests that find significant problems in the software - and now you'll deliberately overlook these problems.
The second problem is that "later" never comes - higher priority work arises and going back to fix up these tests is unlikely to get the priority it needs. Keeping track of which tests are being skipped also adds unnecessary overhead and increases the risk of problems being introduced but going undetected.
Better ways to handle automated test failures
The best measure of success, is how you deal with failure.
- Ronnie Radke
When an automated test fails because of a problem in the software, you should prioritise fixing the problem.
When a test fails but not because of a problem in the software:
If the test is important enough to keep, fix it
If there's no value in the test anymore, delete it
Remember that you've invested the time and effort into writing automated tests for a reason. Quite reasonably, you have doubts about your code and you write tests to help overcome these doubts.
This means the automated test code is important and needs to be high quality.
A big suite of various levels of automated tests can be a great way of quickly identifying problems introduced into the codebase.
As your application changes and the number of automated tests increases over time, though, it becomes more likely that some of them will fail.
It's important to know how to handle these failures appropriately.
There are a lot of different ways to test software. Developers will often write unit or integration tests for their code, but can sometimes fall into the trap of trying to test all things the same way (aka the "golden hammer").
How much does it cost to fix a bug? It depends when it is discovered. If the dev notices it 1 hour after writing it, then it is cheap to fix. If the bug is discovered after it is live and lots of people are using it, then it is much more expensive to fix. If it is discovered after the developer has left the company, then it is super expensive to fix.
A good test strategy employs a combination of different types of testing, performed using an appropriate mix of human testing and automation. Each type of testing is designed to help mitigate different types of risk.
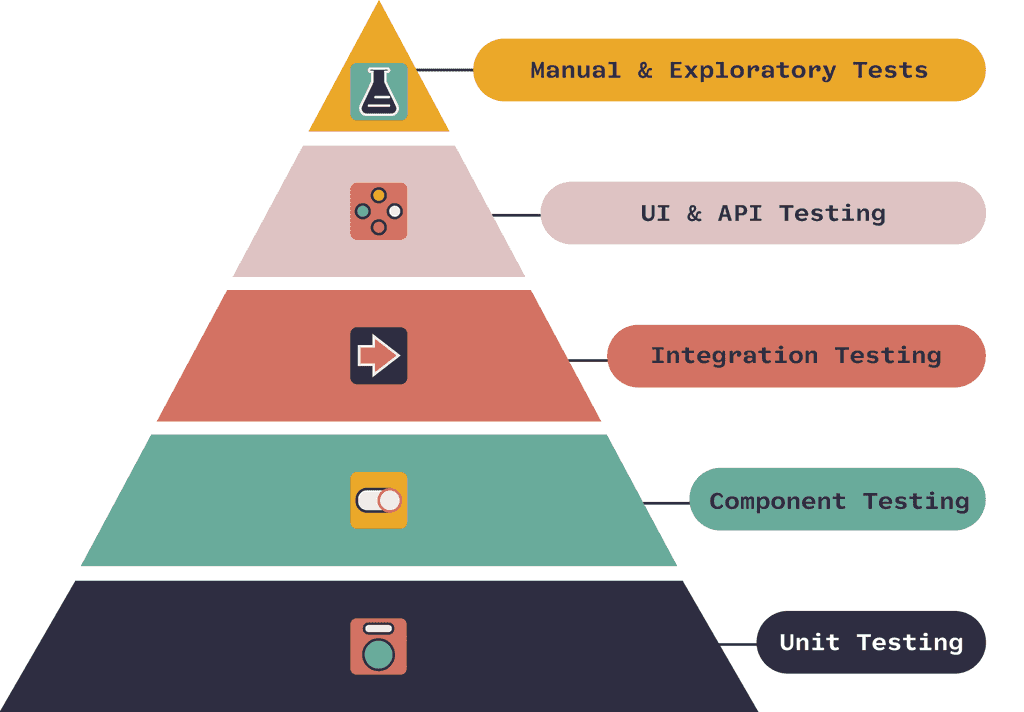
Figure: Testing Pyramid - You should have more unit tests than manual tests
Goals of Testing
The testing pyramid shows the types of tests you will typically use in the Software Development Lifecycle, but it's important to understand how testing types differ from testing goals.
The goal of any test is to identify and mitigate risk.
Different testing types are better suited to different testing goals. For instance, if your goal is to test whether a method you wrote achieves what you intended, the best type of test will probably be a unit test. Alternatively, if your goal is to test that 2 or more applications or services play well with one another, then an integration test would be more appropriate.
What if the goal is to test an entire user journey, to ensure a user can add an item to their shopping cart and complete the checkout process to make a purchase? End-to-end tests!
Note: None of these test types, or test goals, have been described as manual or automated. This distinction describes the "how" of the test. How should you perform an end-to-end test of your purchasing journey? That's a business decision, and you should check out our rule on deciding whether a test is a good candidate for automation.
Video: 5 Types of Testing Software Every Developer Needs to Know! (6 min)
The following list of testing types and their goals is not exhaustive, but covers the more common scenarios you should consider when building a comprehensive test strategy:
Don't confuse test approaches & techniques (focused on the "how") with types of testing (the "what"). For example, exploratory testing - as an approach - applies well to several of the types of testing outlined above.
1. Smoke testing
Smoke testing is designed to verify that the critical functionality of the software is working, at a very high level. The software is put under limited pressure (undergoing only shallow testing) to make sure no smoke comes out.
The smoke test is meant to be quick to execute, with the goal of giving you some assurance that the major features of your system are working as expected.
Smoke tests can be useful right after a new build is made to decide whether or not you can run deeper (and more expensive) tests, or right after a deployment to make sure that they application is running properly in the newly deployed environment.
Why perform smoke testing? To mitigate the risk of the basic and critical functionality failing to work as expected.
2. Unit testing
Unit testing is designed to help mitigate the risk of code changes. Unit tests are designed to be small in scope and they typically consist of testing individual methods and functions of the classes, components or modules used by your software.
Unit tests are generally quick to run and are executed in an automated manner as part of a CI pipeline.
Unit tests are usually written by developers and external dependencies are mocked so that the tests only test the method or function of interest and not anything the method or function might depend on.
Why perform unit testing? To mitigate the risk of code changes.
Integration tests verify that different modules, components or services used by your application work well together. For example, this could be testing interaction with a database or making sure that microservices work together as expected.
For modern applications, integration tests are often implemented using the application's various APIs.
These types of tests are more expensive to run (as they require multiple parts of the application to be up and running) and are typically automated.
Why perform integration testing? To mitigate the risk of problems introduced by different modules or services interacting with each other.
4. Consumer-driven contract testing
Although it falls into the category of integration testing, it's worth calling out consumer-driven contract testing as a separate testing type because it is an excellent way to implement integration testing in microservices-based architectures.
Consumer-driven contract testing is a way of integration testing a service's API prior to deploying it to a microservices-based system. Consumers define their expectations of providers in contracts, which the provider service is then responsible for meeting whenever it makes changes. In this way, a provider service can continue to change, safe in the knowledge that its consumers will not be negatively impacted by their changes. This makes consumer-driven contract testing especially useful when the system under test comprises a lot of independently developed & deployed microservices - and this type of system is essentially impossible to test using more traditional integration testing.
Why perform consumer-driven contract testing? To mitigate the risk that changes to a service impact the consumers of that service.
5. Regression testing
Regression testing is designed to look at unchanged features of the application to make sure that the addition, deletion or updating of features and any bug fixes have not adversely impacted the existing features.
This type of testing is often performed before a deployment or release of the software and can be time-consuming and expensive. Making risk-based selections of which tests to perform and the judicious use of automation can both reduce the time required for regression testing.
Why perform regression testing? To mitigate the risk of intentional code changes causing unintended effects.
6. End-to-end testing
End-to-end testing is designed to replicate user behaviours with the software in a complete application environment. It is a type of system testing that follows a user's (or data's) journey through the system.
While end-to-end tests can be very useful, they're expensive to perform and can be hard to maintain when they're automated. It is recommended to have a few key end-to-end tests and rely more on lower level types of testing (unit and integration tests) to be able to quickly identify breaking changes.
Why perform end-to-end testing? To mitigate the risk of breaking real user's journeys through the software.
7. Acceptance testing
Acceptance testing is designed to verify that the software meets the business requirements. This type of testing requires the entire application to be running while testing and focuses on replicating user behaviours.
A special case is User Acceptance Testing (UAT) in which the software is delivered to the end-users for them to test to make sure it meets their requirements.
Why perform acceptance testing? To mitigate the risk of failing to meet the business/user requirements.
8. Performance testing
You don't want to make headline news, so don't forget about performance testing! (www.hulldailymail.co.uk)
Performance testing is designed to evaluate how a system performs under a particular workload. These tests help to measure the reliability, speed, scalability and responsiveness of an application. For example, a performance test can observe response times when executing a high number of requests or determine how a system behaves with a significant amount of data. It can determine if an application meets performance requirements, locate bottlenecks, measure stability during peak traffic, etc.
Within performance testing, load testing helps you to understand how the system behaves under an expected load, while stress testing helps you to understand the upper limits of the system's capacity using a load beyond the expected maximum.
Why bother with performance testing? To mitigate the risk of surprises when the software is under load.
There are a lot of different ways to test software. Developers will often write unit or integration tests for their code, but can sometimes fall into the trap of trying to test all things the same way (aka the "golden hammer").
How much does it cost to fix a bug? It depends when it is discovered. If the dev notices it 1 hour after writing it, then it is cheap to fix. If the bug is discovered after it is live and lots of people are using it, then it is much more expensive to fix. If it is discovered after the developer has left the company, then it is super expensive to fix.
Good quality automated tests can help your development to continue more quickly and with more safety.
Gating deployments on the successful outcomes of your automated test suites can prevent you from automatically pushing bad code into production.
Depending on your automated tests to make deployment/release decisions means that your test code must be excellent quality.
Figure: Don't make excuses for writing poor quality test code
You're writing (automated test) code because you, legitimately, have doubts about other (product) code, so this automated test code is as important as the production code - and maybe even more important!
The test code should be treated as a first-class citizen, so:
✅ Same best practices - apply your coding best practices to the test code (e.g. clean coding, maintainability, performing code reviews, etc.)
✅ Definition of Done - add all of the levels of automated tests you need to complete to your Definition of Done
❌ "Anyone can write the tests" - don't allocate the work of writing test code to people whose job doesn't normally involve writing production-quality code, the same level of skill is required for the production code and the test code
❌ Tolerate/skip failing tests - refactor the tests as required as you refactor the product code
Watching an automated UI test doing its thing can be very compelling. Combining this with the availability (and powerful marketing) of so many automated UI testing frameworks & tools often leads teams to focus too heavily on automating their testing at the UI level.
This is a classic illustration of the law of the instrument or Maslow's hammer, a cognitive bias that involves an over-reliance on a familiar tool. Abraham Maslow wrote in 1966, "If the only tool you have is a hammer, it is tempting to treat everything as if it were a nail".
While automated UI testing has its place in an overall test strategy (involving both humans and automation), you need to exercise care about how much of your testing is performed at this level.
Figure: Remember that sometimes you need a drill, not a hammer
It's worth looking at Mike Cohn's automated test pyramid:
Figure: Mike Cohn's automated test pyramid (2009)
The topmost layer of the pyramid is deliberately small and represents the relatively small amount of end-to-end UI-based automated checks that should be written and executed against the system.
✅ Customer workflows - Tests at the level of the UI most closely mimic user interaction with the software and so are ideal for checking that the most important customer workflows continue to function as expected
❌ Slow to execute - Testing at this level offers the slowest feedback, since interacting with the user interface is necessarily slower than interacting with smaller units of code within the system
❌ Slow to write - Tests at the UI level are broad in scope and generally slower to write than tests at lower levels
❌ Fragile - These tests are vulnerable to changes in the software's user interface and so are generally much less reliable than tests at lower levels (e.g. unit and service/API tests)
❌ Less deterministic - The scope of automated UI tests is large, so when they fail, they generally don't pinpoint problems in the code as closely as, say, unit or API tests
❌ Hard to test business logic - There is always back-end functionality and business logic that is incredibly hard to "reach" via the user interface and internal infrastructure is nearly impossible to exercise/test via automation at this level
Focusing automated UI testing on important user workflows in your system can be of great benefit. But choose your tests at this high level very carefully and consider using higher value, lower cost alternative types of test lower down the pyramid for the majority of your automated testing.
Watching an automated UI test doing its thing can be very compelling. Combining this with the availability (and powerful marketing) of so many automated UI testing frameworks & tools often leads teams to focus too heavily on automating their testing at the UI level.
This is a classic illustration of the law of the instrument or Maslow's hammer, a cognitive bias that involves an over-reliance on a familiar tool. Abraham Maslow wrote in 1966, "If the only tool you have is a hammer, it is tempting to treat everything as if it were a nail".
While automated UI testing has its place in an overall test strategy (involving both humans and automation), you need to exercise care about how much of your testing is performed at this level.
Automation can be an awesome part of a test strategy, but not all tests are good candidates to be automated.
Not all testing can be completely automated, due to the uniquely human skills that are required (e.g. exploration, learning, experimentation). But even for those tests that can be automated, not all of them should be.
Figure: Making wise decisions about what to automate can prevent you from wasting valuable time automating less valuable tests
If you try to "automate" bad testing, you’ll find yourself doing bad testing faster and worse than you've ever done it before.
- Michael Bolton
Evaluating the value of automation
There are multiple attributes that make a test a good candidate for automation.
Repeatability - How often is the test run?
Complexity - How prone is the test to human error?
Time commitment - How long do testers have to dedicate to completing a test?
Stability - How likely is it that the test will change in the future?
Scale - How much data needs to be run through the test?
Subjectivity - How easy is it to evaluate the test outcome objectively?
Value - How much value does the test provide?
Video: What is automated testing? Beginner intro & automation demo (watch from 5:30 – 7:10)
Repeatability
Consider how often a test is run. If it is run across multiple builds, or if the same test needs to be run on different data sets or browsers then it may be worth automating.
For example, if a test is run on Chrome, edge and firefox then automating it delivers more ROI since that is now 3 less tests the tester has to perform.
Complexity
How easy is it for a human to test? If it requires many inputs where a human might make a mistake, then automating it could be a good idea.
For example, if there was a test for a calculator app and the tester had to enter 20 different inputs before pressing calculate, that would be a good reason to automate since there is a high chance of human error.
Time commitment
Always weigh the time to perform a test against the time to automate it. The longer it takes for humans to perform a test, the higher the value in automating it.
For example, if a test takes 1 hour for testers to perform and automating it takes 2 hours, then after only a few runs the automation will have delivered ROI. However, if a test takes 1 minute to perform but 3 days to automate, then it won't deliver ROI for a long time after automation.
Stability
Functionality that isn't well established or understood is risky to automate. This risk is because the test is liable to change as the requirements change.
For example, if the customer has asked for a new page and the V1 has been delivered, it isn't a good idea to automate the testing of that page just yet because customers and the client will likely have many change requests in the near future.
Scale
Tests that are run on huge data sets are often impractical for humans to perform, and are often better automated.
For example, if a test needs to be run against 5,000 records then it should be automated.
Subjectivity
Some tests are easy to judge objectively, such as the outcome of a maths equation. Those tests often work great when automated. Conversely, tests which require human judgment, such as UX, do not work well when automated.
For example, if the user needs to judge how nice the colours on a page look to the human eye, then it may not be a good idea to automate it because it's subjective.
Value
The more value a test provides, the greater chance it is a good choice for automation.
For example, if a test checks whether the application is going to crash, and it has a high chance of failing then automating it would likely be a good idea since it will ensure it always runs correctly.
✅ Good candidates for automation
Unit tests - Unit tests are often highly objective tests and so are a great first step into automation
Smoke tests - Smoke tests do not require much human input and are repetitive and high value so it's usually a good idea to automate them
Regression and API tests - These tests are highly repeatable and so are often good to automate
Performance and load tests - Tests that look at performance and load often require a great deal of data or interaction making them impractical for humans to perform. As such, they are a good candidate for automation
❌ Don't even think about automation for these tests
Some types of test just don't make sense to even try to automate:
Tests that will only need to be run once - For tests that won't be run again, it doesn't make sense to automate them.
Tests of early stage features - These types of features are liable to change and shouldn't be automated.
Exploratory tests - Experimentation is by it's nature unpredictable so it isn't a good idea to try and automate these tests.
User Experience tests - UX is a very subjective matter, so it's not easy to automate these kinds of tests.
Tests for obscure edge cases - Anything that tests obscure scenarios probably shouldn't be automated because it is unlikely to be a recurring problem.
❔ Take care when deciding to automate these tests
It's not always a black and white decision about whether to automate a test. Let's discuss:
Automating "manual" test cases - Teams are often tempted to take their existing "manual" test cases and automate them, especially as a way to kick off an automated testing project. This isn't necessarily a good approach since the test cases were designed to be performed by humans and not all of their steps probably make sense to be automated, from a value perspective.
Adding automated tests for every bug - It might seem like a good idea to have a policy of adding an automated test for every bug you fix, to help ensure the bug doesn't happen again.
While this can be a valuable policy, you should leave room for exceptions to this rule. Some bugs are merely cosmetic and are unlikely to appear again. A good example of this is the typo - if a developer accidentally entered text that said "Contcat us" instead of "Contact us", it's very unlikely that a developer would ever go into the code and revert to the earlier misspelling.
Practical examples
Let's look at some tests and why we would choose to automate them or not.
Test Scenario: Collapse the sidebar and check that the main pane resizes and displays correctly
Reason: This test is a bad candidate for automation because checking the UI requires a human judgment call, it isn't a precise objective call that a computer can make.
Bad example - Testing a Sidebar
Test Scenario: during video playback, set the “Playback” speed to 1.25 and check that the audio is played faster than before but remains clear.
Reason: In this case, the computer won't be able to easily judge whether the audio is clear or unclear.
Bad example - Testing video playback
Test Scenario: Enter 100 into the amount field and check that the total invoice amount is updated to 110 (GST is added)
Reason: The test is a maths problem which is easy for a computer to evaluate.
Good example - Testing a GST calculation
Test Scenario: Enter “abcdefgh” into the editor, press the “Save” button and save with filename “test”. Close the editor. Open the file “test” and check that it contains “abcdefgh” only.
Reason: It's easy to evaluate the expected output with objective criteria.
Automation can be an awesome part of a test strategy, but not all tests are good candidates to be automated.
Not all testing can be completely automated, due to the uniquely human skills that are required (e.g. exploration, learning, experimentation). But even for those tests that can be automated, not all of them should be.
Having an awareness of the different types and levels of testing is critical to developing appropriate test strategies for your applications.
Remember that different types and levels of tests help to mitigate different types of risk in your software.
There are various models to help with this, most stemming from Mike Cohn's simple automated testing pyramid.
Figure: Mike Cohn's automated testing pyramid (2009)
"All models are wrong, but some are useful"
George Box
The test pyramid is a model and, like all models, it is wrong, though it is perhaps useful.
The core idea of this model is that an effective testing strategy calls for automating checks at three different levels, supplemented by human testing.
The pyramid model shows you where proportionally more automation effort should be placed - so a good strategy would see many automated unit tests and only a few end-to-end (UI-driven) tests.
The pyramid favours automated unit and API tests as they offer greater value at a lower cost. Test cost is a function of execution time, determinism, and robustness directly proportional to the size of the system under test. As automated unit and API tests have a minimal scope, they provide fast, deterministic feedback. In contrast, automated end-to-end and manual tests use a much larger system under test and produce slower, less deterministic and more brittle feedback.
Let's look at the 3 levels of automation in a little more detail.
Unit tests
The pyramid is supported at the bottom by unit tests as unit testing is the foundation of a solid automation strategy and represents the largest part of the pyramid. Unit tests are typically written using the same language as the system itself, so programmers are generally comfortable with writing them (though you shouldn't assume they're good at writing them). Cohn says:
"Automated unit tests are wonderful because they give specific data to a programmer—there is a bug and it’s on line 47. Programmers have learned that the bug may really be on line 51 or 42, but it’s much nicer to have an automated unit test narrow it down than it is to have a tester say "There's a bug in how you're retrieving member records from the database, which might represent 1,000 or more lines of code." These smaller (scope) tests put positive pressure on the design of the code, since it is easier for bigger (scope) tests with poor code to pass than smaller (scope) tests with poor code." - Mike Cohn
Although writing unit tests is typically a developer task within the agile team, there is also an excellent opportunity for testers to be involved by pairing with developers to help them write better unit tests. It's a mistake to assume that developers know how to write good unit tests, since it is unlikely that they have been trained in test design techniques. The tester does not need to know the programming language, the idea is that the developer can talk through the intent of their unit tests and the tester can ask questions that may identify missing coverage or indicate logical flaws. This is an excellent use of a tester's time, since getting a good set of unit tests in place is foundational to the rest of the automation strategy.
Acceptance tests (aka "service tests" or "API tests")
The middle layer of the pyramid - variously referred to as acceptance tests, service tests or API tests - increases the scope of tests compared to unit tests and is often (as Cohn refers to it) the "forgotten layer". While there is great benefit to be gained from automating at this level, it is often ignored or overlooked in automation efforts, especially in teams that are overly-reliant on automated UI tests.
Testing at this level typically requires different tooling because the tests will be manipulating APIs outside of a user interface, so it can be more challenging for testers to be involved here than at the functional UI test level, but a good framework should make it possible for testers to design and write tests at the service/API level too.
Although there is great value in automated unit testing, it can cover only so much of an application's testing needs. Without service-level testing to fill the gap between unit and user interface testing, all other testing ends up being performed through the user interface, resulting in tests that are expensive to run, expensive to write, and often fragile.
End-to-end/UI tests
Automated UI tests should be kept to a minimum, leveraging their value to check that important user workflows continue to work as expected while avoiding the problems associated with their overuse.
An alternative model - the bug filter (Noah Sussman)
Many different test pyramid models have been inspired by Cohn's simple original idea.
An interesting take comes from Noah Sussman who re-imagined the test pyramid as a bug filter (turning the pyramid on its head in the process):
Figure: Noah Sussman's bug filter model (2017)
Note that the area of the bug filter changes at each level. Unit tests focus solely on product code, but integration tests might include databases or external web services. End-to-end tests cover an even larger architecture. Bugs can appear from these new systems without having passed through a previous filter.
I imagine the bugs that drop through this filter as being butterflies in all stages of their lifecycle. Unit tests are going to capture the eggs — bugs before they develop into anything of consequence. Integration tests are going to capture the caterpillars. These may have arisen from a unit test egg that has hatched in the integrated environment, or may have crawled into our platform via a third-party system. End-to-end tests capture the butterflies."
Reliable suites of automated tests can provide a lot of value to your development effort, giving fast feedback and alerting you to unexpected problems introduced by recent code changes.
The more automated the process of building, testing, deploying and delivering software is (and that's the direction a lot of teams are going in), the higher the responsibility of our tests is. Increasingly often, our tests are the only safety net (change detector) between code being written on a developer machine and that code ending up in a production environment. Therefore, it's probably a good idea to make sure that our tests detect the changes we want them to detect.
Automated test code ages just like any other code, though, and it's common to see teams adding more and more automated tests to their suites, without ever going back to review the existing tests to see if they're still relevant and adding value. This process of adding further tests over time often results in bloated test suites that take longer to run and require more human effort to diagnose failures.
Your automated tests require periodic attention and review — or else they're like smoke detectors, scattered throughout enormous buildings, whose batteries and states of repair are uncertain. As Jerry Weinberg said:
Most of the time, a non-functioning smoke alarm is behaviorally indistinguishable from one that works. Sadly, the most common reminder to replace the batteries is a fire."
Jerry Weinberg
Figure: Keep your valuable tests and don't be afraid to throw away irrelevant tests of no value
Tips for reviewing tests
Your automated tests are a valuable asset but only when they are relevant and valuable. So review each of your tests regularly with the following questions in mind.
Don't be afraid to delete tests! - Aim for stability over (perceived) coverage and optimize your automated test suites for the value of the information they provide. It really is a case of quality over quantity, so regularly thinning out old, irrelevant, overly costly and flaky tests is a worthwhile exercise.
Is the test still relevant?
As the product changes over time, older tests can easily still run and pass but are checking for conditions that are no longer relevant.
It may even be the case that tests can no longer fail as the product has evolved, so there is simply no point in running them any more.
Is the test adding value?
A test only adds value if it tells you something useful when it passes and when it fails.
Does the test justify its cost?
The total cost of a test is significant, when you take into account:
The time spent to design, code and maintain it
The infrastructure costs involved in running it (potentially many thousands of times over its life)
The effort involved in diagnosing its failures
The effort involved in regularly reviewing it
So, the value of a test really needs to justify its cost. If a test is not mitigating enough risk or providing enough valuable information compared to its cost, then consider deleting (or at least simplifying) it.
Don't be fooled by "green" tests
Teams can become very focused on achieving "green builds" where all of their automated tests pass during their build pipelines.
Tip: "All green" doesn't necessarily mean "all good"!
False negatives are the silent killers, the tests that show a pass but let a change slip by undetected.
In his blog post on flaky testing, Michael Bolton makes an important point about your "green" tests:
Suppose you and your team have a suite of 100,000 automated checks that you proudly run on every build. Suppose that, of these, 100 run red. So you troubleshoot. It turns out that your product has problems indicated by 90 of the checks, but ten of the red results represent errors in the check code. No problem. You can fix those, now that you’re aware of the problems in them.
Thanks to the scrutiny that red checks receive, you have become aware that 10% of the outcomes you're examining are falsely signalling failure when they are in reality successes. That’s only 10 "flaky" checks out of 100,000. Hurrah! But remember: there are 99,900 checks that you haven't scrutinized. And you probably haven't looked at them for a while.
Suppose you're on a team of 10 people, responsible for 100,000 checks. To review those annually requires each person working solo to review 10,000 checks a year. That's 50 per person (or 100 per pair) every working day of the year. Does your working day include that?
Here’s a question worth asking, then: if 10% of 100 red checks are misleadingly signalling a problem, what percentage of 99,900 green checks are misleadingly signalling “no problem”? They're running green, so no one looks at them. They’re probably OK. But even if your unreviewed green checks are ten times more reliable than the red checks that got your attention (because they’re red), that's 1%. That’s 999 misleadingly green checks.
This is where regular review can help us, as Michael notes in his blog post, On green:
When the check runs green, it's easy to remain relaxed. The alarm doesn’t sound; the emergency lighting doesn't come on; the dog doesn't bark. If we're insufficiently attentive and skeptical, every green check helps to confirm that everything is OK.
When we have unjustified trust in our checks, we have the opposite problem that we have with the smoke detector: we're unlikely to notice that the alarm doesn’t go off when it should.
We can choose to hold on to the possibility that something might be wrong with our checks, and to identify the absence of red checks as meta-information; a suspicious silence, instead of a comforting one. The responsible homeowner checks the batteries on the smoke alarm."
Reliable suites of automated tests can provide a lot of value to your development effort, giving fast feedback and alerting you to unexpected problems introduced by recent code changes.
The more automated the process of building, testing, deploying and delivering software is (and that's the direction a lot of teams are going in), the higher the responsibility of our tests is. Increasingly often, our tests are the only safety net (change detector) between code being written on a developer machine and that code ending up in a production environment. Therefore, it's probably a good idea to make sure that our tests detect the changes we want them to detect.
Automated test code ages just like any other code, though, and it's common to see teams adding more and more automated tests to their suites, without ever going back to review the existing tests to see if they're still relevant and adding value. This process of adding further tests over time often results in bloated test suites that take longer to run and require more human effort to diagnose failures.
Your automated tests require periodic attention and review — or else they're like smoke detectors, scattered throughout enormous buildings, whose batteries and states of repair are uncertain. As Jerry Weinberg said:
Most of the time, a non-functioning smoke alarm is behaviorally indistinguishable from one that works. Sadly, the most common reminder to replace the batteries is a fire."
Exploratory Testing (ET) gives the tester much more freedom and responsibility in their testing than when following a more scripted approach.
Putting some structure around ET helps to make the approach more credible and provides a way for managers to track and review testers' work.
Session-based test management (SBTM) is a lightweight approach to the management of exploratory testing effort that defines a set of expectations for what kind of work will be done and how it will be reported.
[SBTM is] a way for the testers to make orderly reports and organize their work without obstructing the flexibility and serendipity that makes exploratory testing useful
- Jon Bach
Testing in sessions
The "session" is the basic unit of work in exploratory testing (and not, for example, a test case or bug report).
A "session" is an uninterrupted and timeboxed period of reviewable, chartered test effort
Figure: Deep testing requires focus and focus doesn't survive interruption
Breaking this down:
By "uninterrupted," we mean no significant interruptions, no email, meetings, chatting or telephone calls (90 minutes is a common length for such an uninterrupted session - any longer and interruption is almost inevitable).
By "timeboxed," we mean a fixed amount of time after which the session ends, whether the testing is complete or not (60-90 minutes works well as a timebox).
By "reviewable," we mean a report, called a session sheet, is produced that can be examined by a third-party (such as the test lead/manager) that provides information about what happened.
By "chartered," we mean that each session is associated with a mission - what we are testing or what types of problems we are looking for (such charters are descriptive but not prescriptive, and kept short, a couple of sentences at most).
Defining charters
Charters are designed to set the mission for some testing. They should guide the tester without being prescriptive about what they should do. A good template for structuring charters comes from Elisabeth Hendrickson:
Explore (target) with (resources) to discover (information)
Some examples of charters using this template are:
Explore the payment flow with different sequences of events to discover problems with transactions
Explore the chat state model with a random walk of events and transitions to discover surprises
Explore the new security system with existing system capabilities to discover possible privilege escalation risks
The testing for a charter will be in sessions, possibly multiple sessions depending on the scope of the charter and what's discovered during the testing.
Managing tester time
It is acknowledged that there are many non-testing distractions throughout the working day (e.g. meetings, email, and other important - and unimportant! - activities), so typically SBTM allows for 4-5 hours of "on session" time per day for each tester. In this way, we allow for non-testing activities and also leave time for the very important post-session debriefing (see below).
Session reporting via session sheets
Lightweight reporting is a key part of SBTM.
While we want to know what happened during a test session, we don’t want the reporting to be too much of a burden - aim for more time testing and less time writing about testing.
The session sheet is the output artifact from a session and this is designed to be a very simple, standard way of reporting what happened during a session, with a focus on "just enough" detail for debriefing and historical reference, but not too much detail that the tester spends most of their time writing about the session.
Tip: Store your session sheets in the same place as your other project documentation. For example, if your user stories are in Azure DevOps, then add your session sheets to Azure DevOps and link them to the user story so that it's very easy to see the testing that was performed for a particular story.
A few simple metrics are captured in the session sheet, often referred to as the "TBS” metrics:
T - Percentage of session time spent on test design and execution
B - Percentage of session time spent investigating problems (bug reporting)
S - Percentage of session time spent setting up for testing (anything else testers do that makes the first two tasks possible, including tasks such as configuring software & hardware, locating materials, reading manuals, or writing a session report)
These metrics are rough percentages! They are not meant to be accurate to the minute but more designed to reveal whether testing is being blocked by setup problems or overly buggy software not worthy of testing yet.
Apart from the task breakdown metrics, there are three other major parts of the session sheet: bugs, issues, and notes:
Bugs are concerns about the quality of the product, along with their identifiers in the bug tracking system
Issues are questions or problems that relate to the test process or the project at large, ready for discussion during debriefing.
Notes are a free-form record of everything else. Notes may consist of test case ideas, function lists, risk lists, or anything else related to the testing that occurs during the session. It is the notes that provide "just enough" detail about the testing in the session. Mind maps are sometimes used instead of wordy notes as a visual representation of the test effort and the thought processes of the tester.
This mindmap is an example of how session notes could be recorded:
Figure: Notetaking in a mindmap from a session of exploratory testing
Debriefing
A very important - and often overlooked - aspect of SBTM is the idea of session debriefing.
Figure: Debriefing is an opportunity to share your testing story
At the end of each session, the tester gets together with someone else (e.g. their manager or another stakeholder) to talk about the session. James Bach has a handy debriefing checklist to help you ask the right questions during debriefing.
The basic idea of the debriefing is to tell the story of the testing that was done, see what issues or questions arose, and think about charters for further sessions (if required). Debriefing can also be used as an opportunity to provide feedback and coaching to the tester.
This crucial information-gathering exercise is designed to be brief, a maximum of 15 minutes, and omitting these debriefings really does miss out on one of the core aspects of successful SBTM, so resist the temptation to cut this corner. (As testers gain more experience in performing ET in sessions, several related sessions might be covered in the same debriefing.)
The debriefings also help us to learn how much can be done in a test session, and by tracking how many sessions are actually done over a period of time, we gain the ability to estimate the amount of work involved in a test cycle and predict how long testing will take even though we have not planned the work in detail.
Metrics & reporting
Session metrics are the primary means to express the status of the exploratory test effort. They can include the following elements:
Number of sessions completed
Number of problems found
Functional areas covered
Percentage of session time spent testing (the "T" in "TBS", test design & execution)
Percentage of session time spent investigating problems (the "B" in "TBS", bug investigation & reporting)
Percentage of session time spent setting up for testing (the "S" in "TBS", session setup)
A mindmap is also a handy way of reporting on coverage, by using a map of the product and highlighting areas that have been tested, have not been tested, or have significant problems. This visual presentation of test coverage is much easier for stakeholders to interpret than a long wordy document or complex spreadsheet.
Tips for getting started
If you are currently running testing from scripted test cases, try using SBTM by having charters for the target of each test case and then running sessions, rather than following the exact steps of the test case.
Once you become familiar with managing your test effort in sessions, try reporting your test results using an SBTM approach too (keeping any existing reporting requirements in place if need be) and educate consumers of your test reporting as to their content.
During Sprint planning, consider estimating how many sessions will be required for each story allocated in the Sprint. Knowing how many testers you have available and how many sessions each tester can reliably complete per day, you can calculate your "tester velocity" (in terms of number of sessions per Sprint) to see whether you can realistically complete the testing of the stories within the Sprint timeframe. This early signal is helpful in not committing too much work to the Sprint and reinforces the idea that stories are not finished unless they are also well tested.
Exploratory Testing (ET) gives the tester much more freedom and responsibility in their testing than when following a more scripted approach.
Putting some structure around ET helps to make the approach more credible and provides a way for managers to track and review testers' work.
Session-based test management (SBTM) is a lightweight approach to the management of exploratory testing effort that defines a set of expectations for what kind of work will be done and how it will be reported.
[SBTM is] a way for the testers to make orderly reports and organize their work without obstructing the flexibility and serendipity that makes exploratory testing useful
- Jon Bach
While user stories should have good acceptance criteria, checking that these criteria are met is really just the starting point before engaging in deeper testing.
Without detailed test cases, it can be difficult to work out what to test outside of the acceptance criteria. Using test ideas and heuristics to come up with these ideas are important skills for good exploratory testing.
Taking an exploratory approach to testing gives testers more freedom to choose what to test and how to test, but they can then find it hard to decide what to test.
It's helpful to think in terms of test ideas.
Test ideas
Test ideas are brief notions about something that could be tested - Rikard Edgren
Test idea: an idea for testing something - James Bach
When tasked with testing something new, you don't necessarily know how to unearth interesting test ideas and so following rules probably doesn't help.
Under such conditions of uncertainty (which are normal in software development), look for methods or ways of coming up with test ideas that might work, while acknowledging that they might not - these are heuristics.
Heuristics
A heuristic is a fallible method for solving a problem or making a decision.
A heuristic is an experience-based technique for problem solving, learning and discovery.
A heuristic is a way to help me come up with test ideas - Lee Hawkins
You'll likely build up your own toolbox of heuristics to draw from as you become more familiar with them and realise their power.
Getting started - consistency heuristics
To get started with the use of heuristics, try some consistency heuristics. A great example comes from Michael Bolton in the form of HICCUPPS, which is a mnemonic as follows:
History. We expect the present version of the system to be consistent with past versions of it.
Image. We expect the system to be consistent with an image that the organization wants to project, with its brand or with its reputation.
Comparable Products. We expect the system to be consistent with systems that are in some way comparable. This includes other products in the same product line; competitive products, services, or systems; or products that are not in the same category but which process the same data; or alternative processes or algorithms.
Claims. We expect the system to be consistent with things important people say about it, whether in writing (references, specifications, design documents, manuals, whiteboard sketches, etc.) or in conversation (meetings, public announcements, lunchroom conversations, etc.).
Users' Desires. We believe that the system should be consistent with ideas about what reasonable users might want.
Product. We expect each element of the system (or product) to be consistent with comparable elements in the same system.
Purpose. We expect the system to be consistent with the explicit and implicit uses to which people might put it.
Statutes. We expect a system to be consistent with laws or regulations that are relevant to the product or its use.
As an example of using the "Product" part of this heuristic, note that in Trello, there is an inconsistency in the way fields on cards can be edited. Clicking in the Description or Tasks fields puts the field straight into Edit mode, whereas to edit a Comment requires an explicit click on the "Edit" action. This is a case of the Trello product being inconsistent with itself in terms of editing fields on a card.
While user stories should have good acceptance criteria, checking that these criteria are met is really just the starting point before engaging in deeper testing.
Without detailed test cases, it can be difficult to work out what to test outside of the acceptance criteria. Using test ideas and heuristics to come up with these ideas are important skills for good exploratory testing.
When asked how they spotted a problem, testers often say things like "based on my experience of the product" or "by comparing the product against the specification".
It's worth noting that users often find problems in your software without ever having seen a specification or user story!
So, how do you recognize when you've found a problem? The key concept here is the oracle.
Oracles
An oracle is a heuristic principle or mechanism by which someone recognizes a problem.
Oracles are, by their nature, heuristic. That is, oracles are fallible and context-dependent.
Oracles do not tell us conclusively that there is a problem; rather, they suggest that there may be a problem.There can be no absolute oracle, so we use many.Consistency is an important theme in oracles.
As an example, we can detect a bug when the product behaves in a way that is inconsistent with its specification or user story.
An example oracle
The oracle here is the specification or user story and the problem is that the state of the product is not consistent with that oracle.
The problem might be caused by an out-of-date specification, a genuine bug in the product or something else – or there might actually be no problem at all!
Tip: Take the conscious step to understand which oracle you are using to spot a potential problem.
By doing this, you move away from personal opinion towards proof. This is a key step to enhancing your credibility in the eyes of your stakeholders.
Your bug reports are more credible when stakeholders clearly understand why you are claiming your observation to be a potential problem.
When asked how they spotted a problem, testers often say things like "based on my experience of the product" or "by comparing the product against the specification".
It's worth noting that users often find problems in your software without ever having seen a specification or user story!
So, how do you recognize when you've found a problem? The key concept here is the oracle.
In the old days, you had to deploy your entire application to a staging environment just so you could share it with other members of your team. That process was a huge hassle and made it much harder to get feedback quickly.
Luckily, port forwarding is the silver...errr...golden bullet that solves this issue. Port forwarding helps by exposing a locally running application over the internet for testing or other purposes.
3rd party solutions have existed for awhile, but they need configuration and cost money. Now, Dev Tunnels is a new port forwarding feature in Visual Studio that can help developers do that for free.
Video: Simplify Remote Testing with Dev Tunnels | Daniel Mackay | SSW Rules (7 min)
Use Cases
Feedback on a locally running application
Testing of an application on a mobile phone or tablet
Webhooks: public service needing to make an API call to your local website (e.g. Twilio or Sendgrid webhook)
Azure SignalR: Get the Azure hosted signal R service to send websocket messages to your local website
Azure APIM: Use APIM as a gateway that points to a locally running API
Power Platform: Debug Power Platform by running your API locally
Locally testing applications which need to communicate on a port blocked from your environment (i.e. using a Jump Server)
Dev Tunnels is currently only available via Visual Studio 2022 17.5+
Pre-Requisites
Visual Studio 2022 17.5+
ASP.NET Core project
Usage
Enable the Dev Tunnels via Tools | Options | Environment | Preview Features:
Figure: Enabling Dev Tunnels
Open the Dev Tunnels window via View | Other Windows | Dev Tunnels
Create and configure a new Dev Tunnel:
Figure: Configuring a Dev Tunnel
Run the website
Get the public URL via Dev Tunnels | Tunnel URL:
Figure: Finding the Dev Tunnel URL
Confirm you can browse your site via the public URL:
Figure: Testing the Dev Tunnel on desktop
Confirm you can browse via a mobile:
Figure: Testing the Dev Tunnel on mobile
Best Practices on Access Types
Private: Ideal if you are testing yourself on mobile device
Organization (Recommended): Ideal if you need feedback from others within the organization
Public: For when the other two options are not possible (e.g. Web hooks). In this case it is recommend to use Temporary tunnels so that the URL is no longer available once you've closed visual studio
In the old days, you had to deploy your entire application to a staging environment just so you could share it with other members of your team. That process was a huge hassle and made it much harder to get feedback quickly.
Luckily, port forwarding is the silver...errr...golden bullet that solves this issue. Port forwarding helps by exposing a locally running application over the internet for testing or other purposes.
3rd party solutions have existed for awhile, but they need configuration and cost money. Now, Dev Tunnels is a new port forwarding feature in Visual Studio that can help developers do that for free.
When testing code that depends on Entity Framework Core, the challenge often lies in how to effectively mock out the database access. This is crucial for focusing tests on the functionality surrounding the DB access rather than the database interactions themselves. The EF Core In-Memory provider is a tool designed to address this need.
Common Pitfalls in Mocking
Trying to Mock DbContext
Attempting to mock the entire DbContext is a common mistake. This approach typically leads to complex and fragile test setups, making the tests hard to understand and maintain.
varmockContext = newMock<ApplicationDbContext>();// Adding further mock setups...
Figure: Bad Example - Mocking the entire DbContext is overly complex and error-prone.
Trying to Mock DbSet
Similarly, mocking DbSet entities often results in tests that don't accurately reflect the behavior of the database, leading to unreliable test outcomes.
Figure: Bad Example - Mocking DbSet entities fails to mimic real database interactions effectively.
Good Practice: Using DbContext with In-Memory Provider
Instead of extensive mocking, using DbContext with the EF Core In-Memory provider simplifies the setup and reduces the need for mocks. This approach enables more realistic testing of database interactions.
Figure: Good Example - Using DbContext with an EF Core In-Memory provider for simpler and more effective testing.
Caveat: Limitations of In-Memory Testing
While the EF Core In-Memory provider is useful for isolating unit tests, it's important to recognize its limitations:
Behavioral Differences: It doesn't emulate all aspects of a SQL Server provider, such as certain constraints or transaction behaviors.
Not Suitable for Query-focused Tests: For tests that focus on EF queries, more realistic results can be achieved through integration tests with an actual database.
When testing code that depends on Entity Framework Core, the challenge often lies in how to effectively mock out the database access. This is crucial for focusing tests on the functionality surrounding the DB access rather than the database interactions themselves. The EF Core In-Memory provider is a tool designed to address this need.
Ephemeral environments are like temporary, disposable workspaces created for a specific purpose, and they're often thrown away once they're no longer needed. Here's how they come in handy across various tasks:
Video: Use ephemeral development environments for mission-critical workloads on Azure (2 min)
Testing
They're particularly useful for creating isolated testing environments. Imagine running a test to ensure a new feature works as expected. Ephemeral environments allow you to spin up a clean, separate space to run that test without affecting your main application. Once the test is complete, the environment is discarded, ensuring a fresh start for each test run.
CI/CD
In the world of Continuous Integration and Continuous Deployment, these environments are a game-changer. They enable you to automatically build, test, and deploy applications, ensuring everything runs as expected before going live. The environment is created on-demand for the pipeline, then discarded once it's done.
Feature Development
For developers working on new features or bug fixes, ephemeral environments provide a sandbox to experiment and test changes without risking the stability of the main application. It's like having a safe space to try out new ideas, which can be thrown away once the development work is finished.
Training and Demos
Ephemeral environments are also great for creating temporary setups for training sessions or product demos. They can be configured with the necessary data and settings, providing a consistent experience for each session, and then removed afterward.
In summary, ephemeral environments offer a versatile solution for ensuring clean, isolated, and repeatable workspaces across testing, development, and demonstrations in software applications.
Ephemeral environments are like temporary, disposable workspaces created for a specific purpose, and they're often thrown away once they're no longer needed. Here's how they come in handy across various tasks:
Video: Use ephemeral development environments for mission-critical workloads on Azure (2 min)
Before any project can be used by a customer it must first be published to a production environment. However, in order to provide a robust and uninterrupted service to customers, it is important that the production environment is not used for development or testing purposes. To ensure this, we must setup a separate environment for each of these purposes.
Bad example - Skipping environments
Skipping environments in a feeble attempt to save money will result in untested features breaking production.
What is each environment for?
Production: Real data being used by real customers. This is the baseline/high watermark of all your environments. Lower environments will be lower spec, fewer redundancies, less frequent backups, etc.
Staging: 'Production-like' environment used for final sign-off. Used for testing and verification before deploying to Production. Should be as close to Production as possible e.g. access (avoid giving - developers admin rights), same specs as production (especially during performance testing). However, this is not always the case due to cost implications. It is important that staging is 'logically equivalent' to production. This means having the same level of redundancy (e.g. Regions + Zones), back-ups, permissions, and service SLAs.
Development: A place to verify code changes. Typically, simpler or under-specified version of Staging or Production environments aiding in the early identification and troubleshooting of issues (especially integration).
Ephemeral: Short-lived environment that is spun up on demand for isolated testing of a branch, and then torn down when the branch is merged or deleted. See rule on ephemeral environments.
Local: Developer environment running on their local machine. May be self-contained or include hosted services depending on the project's needs.
What environments should I create for a new project?
Large or Multi-Team Projects
Good example - Large or Multi-Team Projects tend to have more environments
For large projects it's recommended to run 4 hosted environments + 1 local:
Production
Staging
Development
Ephemeral (if possible)
Local
The above is a general recommendation. Depending on your project's needs you may need to add additional environments e.g. support, training, etc.
Internal or Small Projects
Good example - Internal or Small Projects have fewer environments
For smaller projects we can often get away without having a dedicated development environment. In this scenario we have 2 hosted environments + 1 local:
Production
Staging
Local
Before any project can be used by a customer it must first be published to a production environment. However, in order to provide a robust and uninterrupted service to customers, it is important that the production environment is not used for development or testing purposes. To ensure this, we must setup a separate environment for each of these purposes.
Bad example - Skipping environments
Skipping environments in a feeble attempt to save money will result in untested features breaking…