Rules to Better Web API - 5 Rules
Want to build a Web Application or API? Check SSW's Web Application / API consulting page.
REST is well established and most developers choose it by default when starting a new project. But now we have a choice and, depdending on your requirements, there may be a better option.
We rarely build standalone, self-contained applications anymore, and if you're building a data driven solution, you will have components that need to talk to each other somehow. This is usually a UI, which is occasioanlly a desktop rich client but more often a SPA or mobile app, and a back end. We achieve this by exposing an API on our back-end that our front-end client UI can talk to.
REST is well established as the protocol for this and most developers would choose this without giving it a second thought. But there are 2 other major players now, and depending on your requirements these could be better options for you.
REST
REST is built on top of HTTP and adopts the HTTP verbs to send and request data. REST and HTTP are both well understood by most developers, operating systems, runtimes and HTTP stacks, so using REST gives you confidence that your solution will run nearly anywhere. Also, by taking advantage of the HTTP protocol, you benefit from a lot of features this brings you out of the box, like being able to transfer rich content like videos and images, client-side caching out fo the box, and standardised response codes that other developers can understand if they are consuming your API.
gRPC
gRPC, developed by Google, uses protobuf files (rather than JSON) for its payload and transfers over HTTP/2 rather than over HTTP. protobuf files define your payload and are human readable files, but the payload itself is serialized into binary, leading to much smaller transfer sizes. Additionally, HTTP/2, which is more a successor to HTTP rather than an incremental version increase, is much faster.
The result is that gRPC offers more efficiency (less bandwidth) and better performance (faster) than REST. gRPC is open source and there are libraries for most platforms, runtimes and languages. If performance is of a primary concern, gRPC may be the best option for you. However, as gRPC uses HTTP/2, and HTTP/2 is not yet as widely supported and implemented as HTTP, y ou must consider whether your client applications will be able to leverage this technology.
For more information, see our rule: Do you know when to use gRPC?
GraphQL
GraphQL is a query language for APIs, developed by Facebook and open-sourced in 2015. GraphQL enables API or back-end developers to expose a flexible query interface, rather than well-defined data resources or view models, that front-end developers can consume. GraphQL is good for when you want to expose your entire data set to your consumers, or when you are ready to build your back-end, but your front end requirements are not yet well defined.
For more information, see our rule: Do you know when to use GraphQL?
1, 2, or all 3
The best thing about all of these is that they are not mutually exclusive. You can use combinations of them that best suit your needs, rather than compromising to find the best general fit.
NOTE: Some people might consider this a '3-headed beast'; the more you implement, the more you have to support. There could be scenarios where 2 or more of these options are a great fit and the right choice, but make sure you consider this carefully.
GraphQL is a query language for your APIs. It lets you expose a schema, which is a combination of types, queries, and mutations and your client applications can define their own queries based on that schema. You can think of it as SQL for the web.
GraphQL was developed by Facebook in 2012 to solve a problem with their mobile app, which was chewing users' data and battery and leading to negative reviews. This is because the Facebook newsfeed combines data from many entities and data sources, which required multiple API calls. GraphQL allowed them to retrieve all the data they need with 1 call.
GraphQL is a query language; it is agnostic of database, programming language, OS, and platforms. To enable GraphQL, you can use client and server libraries (see Resourced below).
There are GraphQL server and client libraries for nearly all of these (see the Resources section below), which you can add to your existing projects to enable GraphQL.
Key Terms
GraphQL differs from REST in that REST is concerned with resources and GraphQL is concerned with state . While some features are somewhat analogous, it helps to be familiar with the GraphQL lingo and understand it in its own right. For more information, see "Thinking in Graphs".
- Types: Types are the fundamental building blocks of your GraphQL API. Just like in a strongly typed language like C#, there are a default set of types, and you build your own by putting together default and custom types as fields of other types. See more on graphql.org/learn/schema/#type-system.
- Queries: GraphQL queries return the current state of the data source(s). Being a query language, you specify which fields you want the server to return – these can be any fields supported by the schema, including for related types. Your query is interpreted by the server and used to fetch data to pass back to the requesting client. One of the most powerful features of GraphQL is not just that it doesn’t care what the data source is, but schema stitching allows you to aggregate data from multiple sources and return it to your client with one query. Those data sources could be different entities or database tables, different databases, or even flat files on a server, or other GraphQL (or REST) APIs. See more on graphql.org/learn/queries.
- Mutations: Mutations change the state of the data source(s) that the GraphQL server exposes, similar to create, update, or delete operations. See more on graphql.org/learn/queries/#mutations.
- Schema: Your GraphQL schema is the complete map of data your GraphQL server exposes. This defines all the data that your clients can request, and all the changes they can make. Specific queries or mutations are not explicitly defined; rather, you specify their structure. Just like with a SQL database, you write whatever queries you want against it, and if the schema supports them, they will run successfully.
Advantages of GraphQL
- No under-fetching: Sometimes a REST resource may only give you part of what you need. For example, if you need to know all the orders placed by a customer, what date they were ordered, and their current status, but the initial customer search resource only returns the details of the customer, this is called under-fetching. You then need to use the customer’s ID to query your orders resource for all orders matching that customer ID.
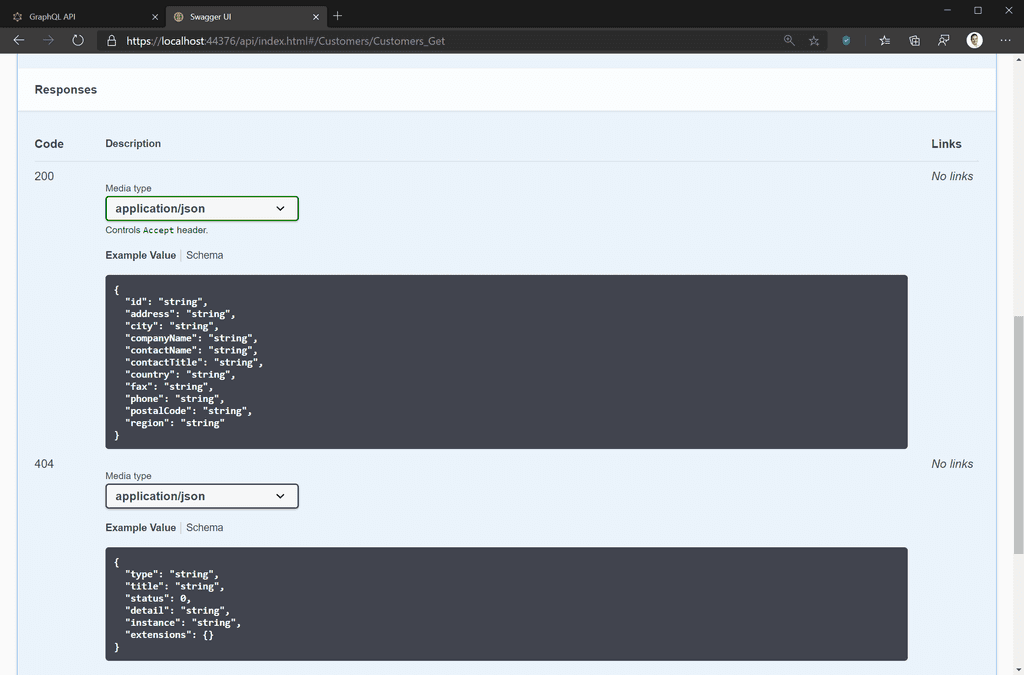
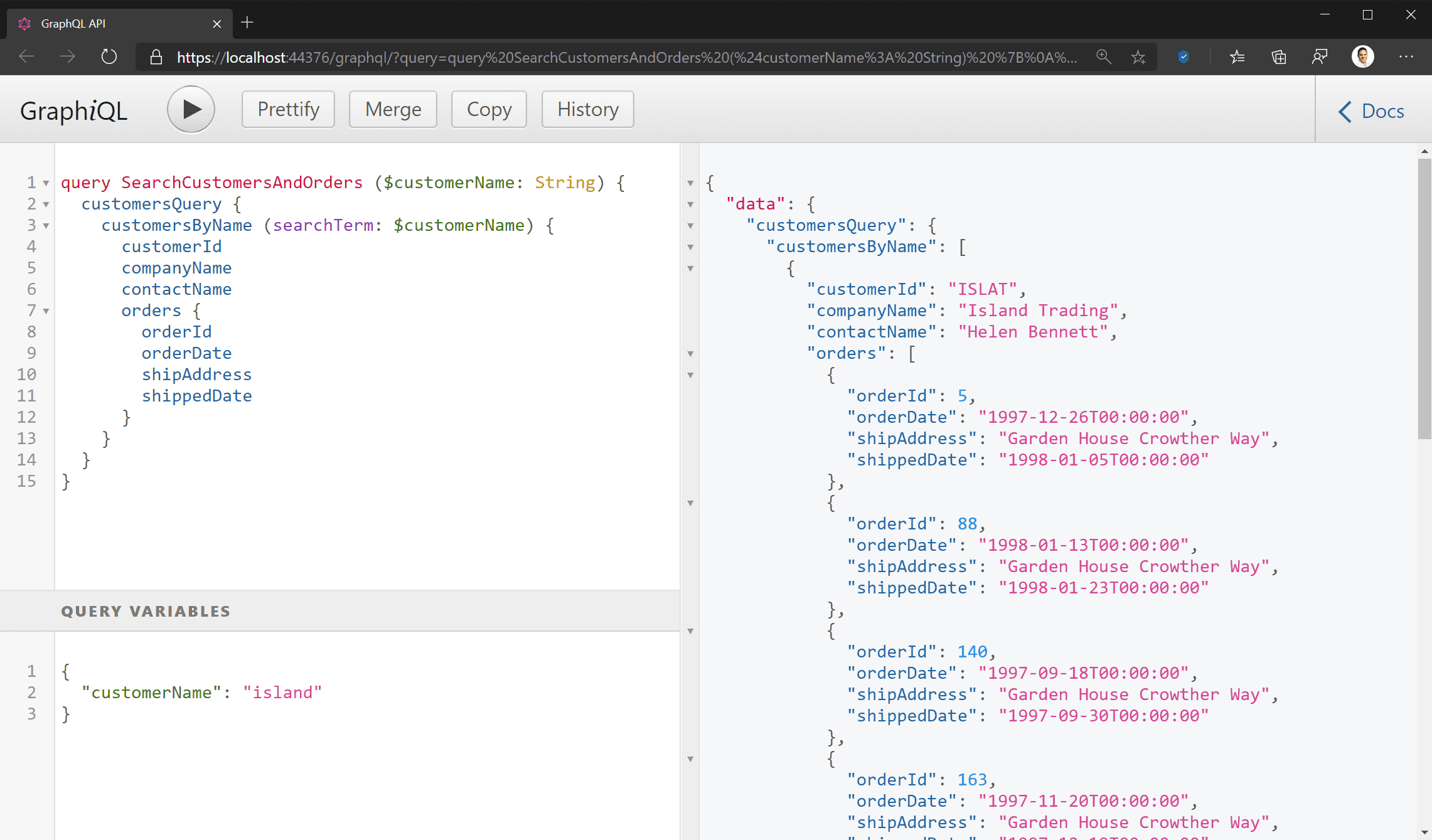
Figure: Bad example – REST API does not return order information with a customer query, so a second API call is needed - No need for over-fetching: Continuing the above example, you may decide a workaround is to return details of all orders with all customer queries. However, this overwhelms your client with data it doesn’t need most of the time, just to solve a problem in one scenario. This is called over-fetching (and is the specific problem Facebook set out to resolve with GraphQL).
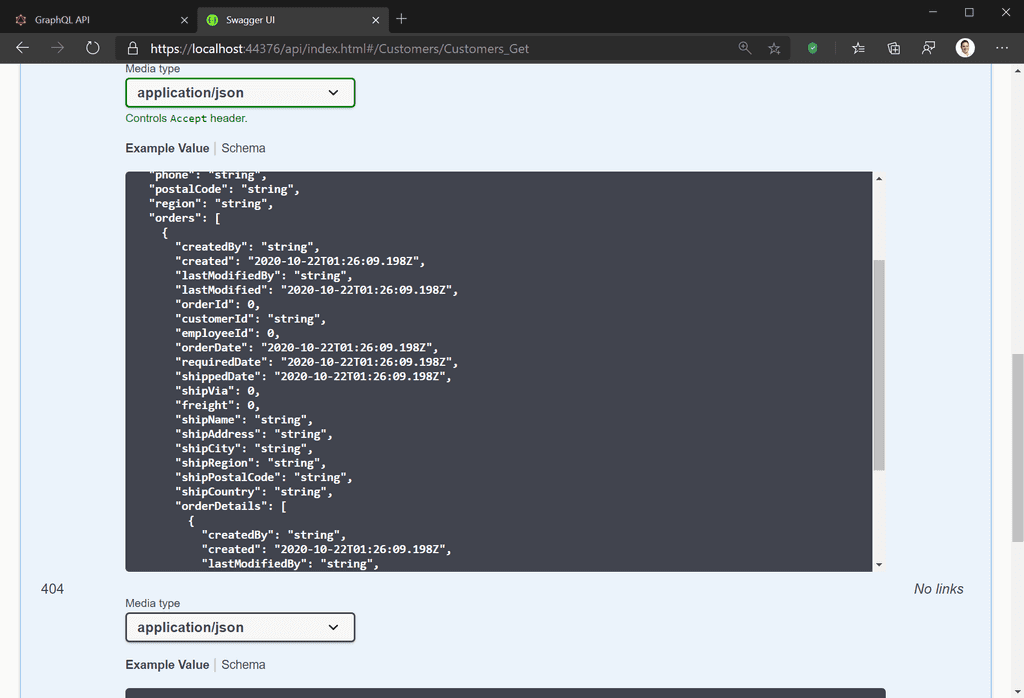
Figure: Bad example – REST API returns a whole bunch of data the client doesn’t need – killing bandwidth (and, on mobile, battery) - Client Defined Queries: In a REST API, the CRUD operations are defined by the API, and the client application is constrained by the operations available. This means that any changes required by your UI necessitate changes to your back end as well. With GraphQL you can change your client queries to meet changing UI needs without needing to update your back end.
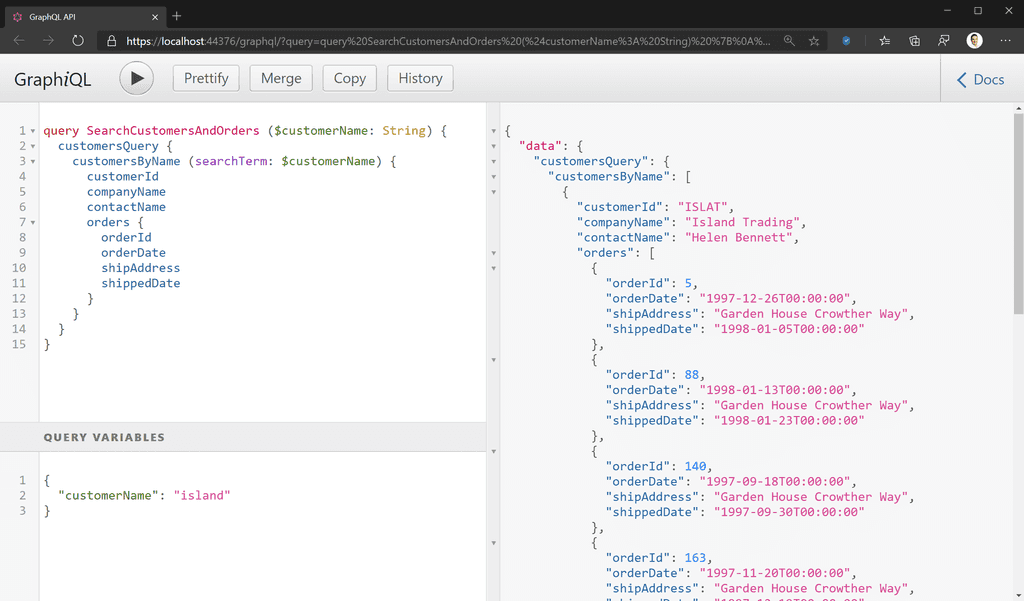
Figure: Good example – Clients can write queries and specify which fields they want the query to return Disadvantages of GraphQL
Sounds great, right? Well, there are some limitations to be aware of before you rush to add it to all your solutions.
- No caching: With the exception of the POST HTTP verb, REST calls are idempotent. This means that for any REST call, if the parameters are the same, the result will always be the same. And as REST is built on top of HTTP, and most HTTP stacks have caching built-in, you get client-side caching for free with REST. With GraphQL, this is not possible. If you want to take advantage of caching, it needs to be server-side and requires effort on the part of the developer.
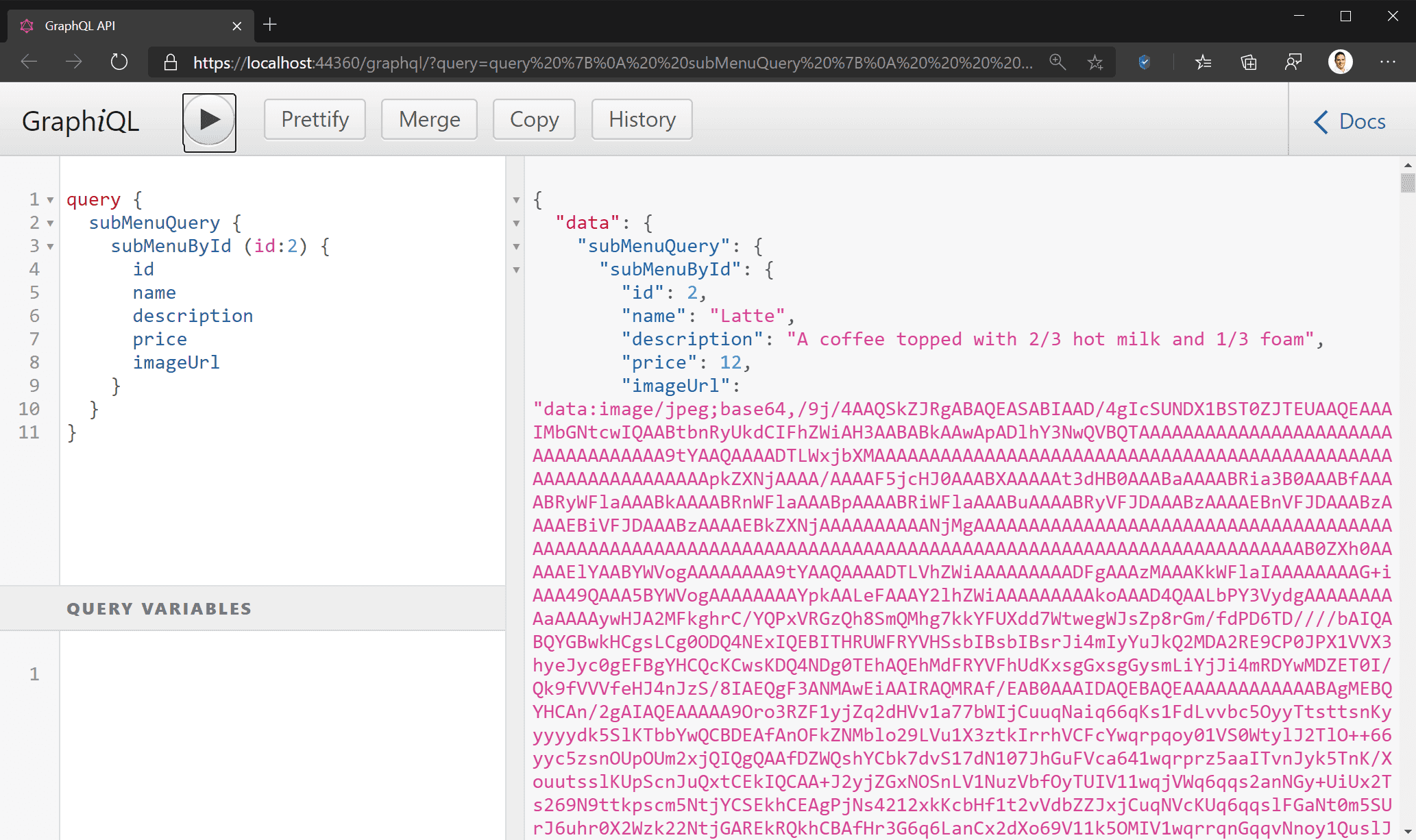
- Not suitable for rich content: GraphQL is a query language, and is fundamentally meant for data. Rich content, like images and videos, is not best suited to GraphQL. GraphQL is a text-based specification, and while it is possible to (for example) encode images into Base64 strings and send them as a field in your GraphQL type, this is not the best way to do it. This is analogous to storing BLOBs in your SQL database – you can do it, but it’s not a good idea.
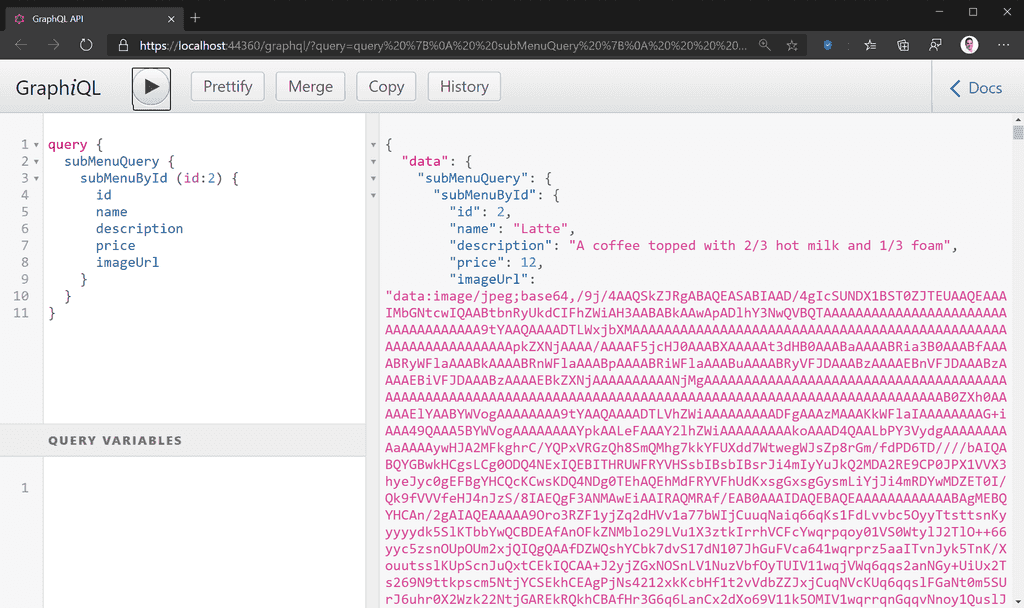
Figure: Bad example – Image encoded as Base64 string uses more bandwidth and processing power than necessary, resulting in poor UX When to use GraphQL
GraphQL is useful when your client needs to display information from multiple sources in one UI as it can service complex queries in your client applications without multiple round-trips to the server. However, this can also be achieved with REST - you can build carefully crafted view models that explicitly meet the needs of the views in your UI.
The best use case for GraphQL is when the needs of the consumer (e.g. your client application) are not well known. For example, you might have a good definition of your data model, and a team ready to start work on your back end, but no design or team for your UI or client application yet. Or you might have an existing solution and want to provide an integration API that can be consumed by different clients or other applications.
Some example use cases might include:
- A hospital application suite: A hospital has different departments that need very different client applications - OR and ICU need patient monitoring, Admissions need a booking system, and the Wards need medication management. But they all have to access the same data. This would be a good candidate for a GraphQL back end.
- An aggredate UI for an existing portfolio of applications: An enterprise may have a full suite of line of business applications, all of which work well in their respective areas. But management want a single pane of glass to access management inforamtion across the whole enterprise. Rather than replacing everything with a single ERP - which may meet mostof the needs of most of these areas, but compromises functionality for all of them, you could build a GraphQL API to unify and expose data from all of them that can be consumed by a built for purpose applciation for management. Note: You may be able to achieve similar results with PowerBI or a similar tool.
- A public database: If your product is your data, and you make it available for people to consume in their own applications, providing a GraphQL endpoint lets them consume the data in a way that meets the needs of their applicaiton, rather than in a way that the API has defined.
GraphQL is not a replacement for REST; in fact, it’s often best to use them together. While GraphQL supports changing state on the server through migrations, the true power of GraphQL is in queries. Many create, update, and delete operations are relatively unchanging and can benefit from being maintained as REST resources – think sign-up forms for example. REST is also better for transferring rich content, like images and videos.
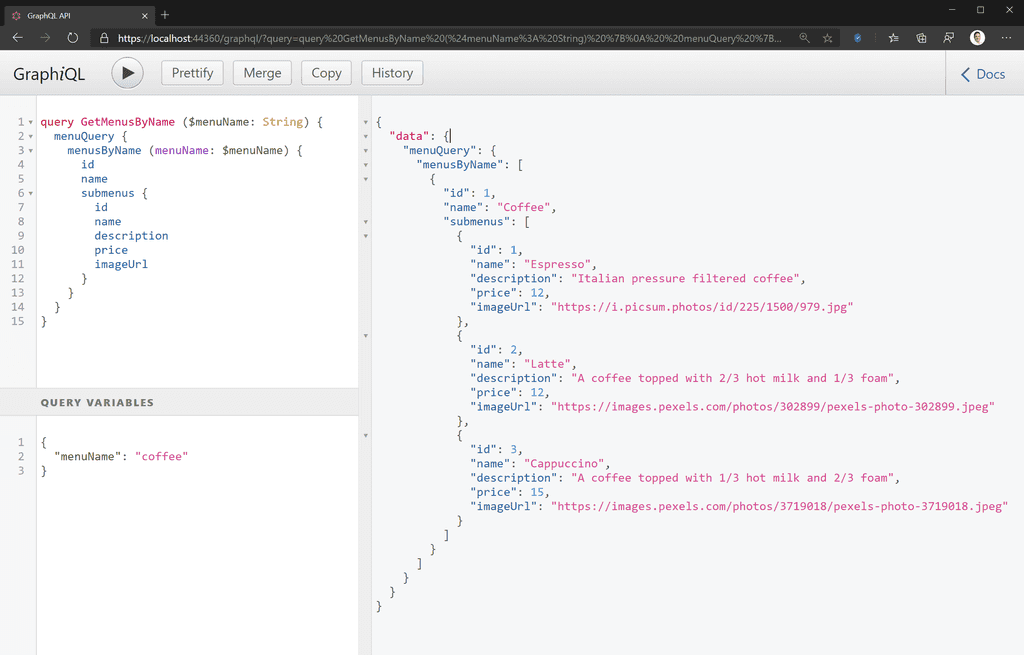
Figure: Good example – GraphQL used to construct a complex query with embedded entities, and images are referenced with a URI that the client can use to retrieve from a REST endpoint Adam Cogan introducting SSW People explains how GraphQL can be combined with other technologies to get the best results.
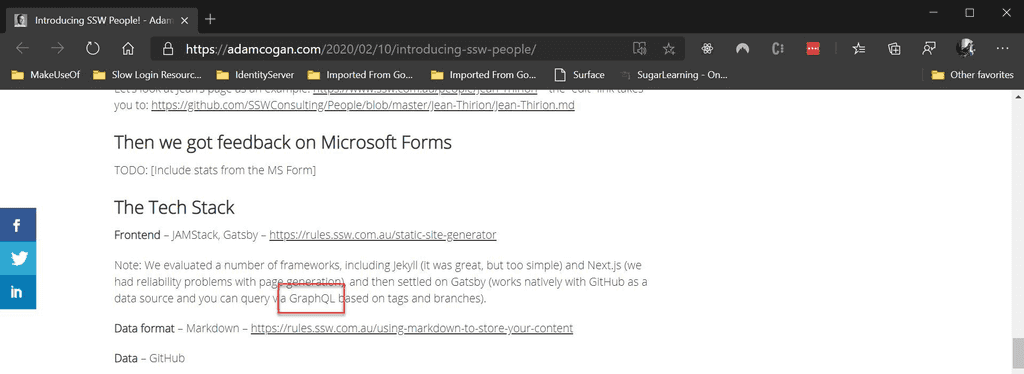
Figure: Good example - Use GraphQL to complement the rest of your tech stack 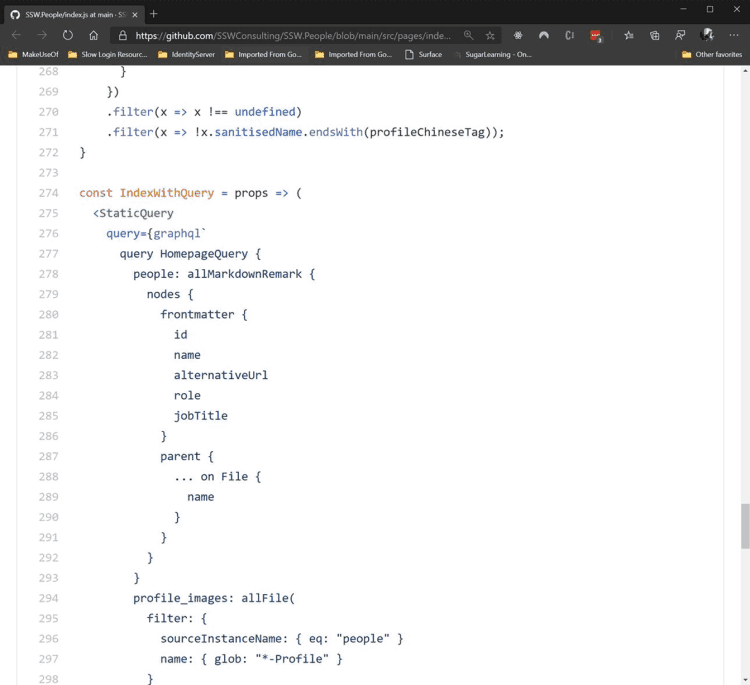
Figure: Good example - GraphQL query in the SSW People static web app The best GraphQL libraries
- For .NET, there are a few GraphQL libraries. The best known is GraphQL.Net which has client and server libraries. But the best library for .NET is Hot Chocolate. Hot Chocolate, and the associated tools and libraries, are all named after desserts, which is bad, but despite this, these are the best tools for working with GraphQL in .NET.
- For JavaScript, there are lots of GraphQL libraries. But Apollo is the best one. Apollo is a commercial data platform, with free and paid offerings, but they have free and open source client and server GraphQL libraries. See more on github.com/apollographql.
Good error design is as important to the success of an API as the API design itself. A good error message provides context and visibility on how to troubleshoot and resolve issues at critical times.
REST API
Use the correct HTTP Status Codes
The HTTP/1.1 RFC lists over 70 different HTTP Status Codes. Only some developers will be able to remember all of them, so it pays to keep it simple and use the most common Status Codes. Below are the most common HTTP status codes:
-
2XX - Success. Examples:
- 200 OK - Generic success response.
-
4XX - Client errors. Examples:
- 400 Bad Request - The server cannot understand the request.
- 401 Unauthorised - Invalid/non-existent credential for this request.
-
5XX - Server errors. Examples:
- 500 Internal Server Error - The server encountered errors preventing the request from being fulfilled.
Use ProblemDetails Format
RFC 7807 - Problem Details for HTTP APIs details the specification for returning errors from your API.
Problem Details defines a standardised way for HTTP APIs to communicate errors to clients. It introduces a simple and consistent format for describing errors, providing developers with a clear and uniform way to understand and handle errors in HTTP APIs.
Below is an example of an error message in Problem Details format:
{ "type": "https://example.com/probs/invalid-id", "title": "Invalid ID", "status": 400, "detail": "The provided ID has invalid characters.", "instance": "/account/12%203", "allowedCharacters": "^[a-zA-Z0-9]+$" }In the above example:
typespecifies a URI that uniquely identifies the type of the problem.titleprovides a short, human-readable summary of the problem.statusindicates the HTTP status code for the response.detailgives a human-readable explanation specific to the occurrence of the problem.instanceprovides a URI reference that identifies the specific occurrence of the problem.allowedCharactersis an example property specificly added to the problem.
Using the above structured message format, APIs can now reliably communicate problems to clients to enable better error handling.
Use .NET Exception Handler
ASP.NET Core has built-in support for the problem details specification since .NET 7.
Option 1 - Use built-in ProblemDetails service
// Program.cs // This adds ProblemDetails service // Read more on https://learn.microsoft.com/en-us/aspnet/core/fundamentals/error-handling?view=aspnetcore-8.0#problem-details builder.Services.AddProblemDetails(); ... // This instructs the API to use the built-in exception handler app.UseExceptionHandler();Using this option, the API will generate a problem details response for all HTTP client and server error responses that don't have body content yet.
You can also customise the
ProblemDetailsServicebehaviour - read more about it in the following link Handle errors in ASP.NET Core | Customise Problem Details.⚠️ Important On certain templates, the default .NET Exception Handler middleware will only produce ProblemDetails responses for exceptions when running in a non-Development environment. See Option 2 below on how to make this consistent across environments.
Option 2 - Customise Exception Handler Middleware (Recommended)
This option provides more flexibility in controlling the API's behaviour when it encounters thrown exceptions. Read more about it here. By Customising the
ExceptionHandlermiddleware, developers have complete control over what format endpoints should return under a particular scenario.Below is an example of customising the
ExceptionHandlermiddleware to produce aProblemDetailsresponse for any exception.app.UseExceptionHandler(exceptionHandlerApp => exceptionHandlerApp.Run(async context => { // Obtain the exception Exception? exception = context.Features.Get<IExceptionHandlerFeature>()?.Error; // Produce a ProblemDetails response await Results.Problem( statusCode: StatusCodes.Status500InternalServerError, type: "https://tools.ietf.org/html/rfc7231#section-6.6.1", title: exception?.Message ).ExecuteAsync(context); }));API will produce consistent response formats in any environment using the above approach.This approach is the recommended approach for frontend and backend development.
Any API (REST, gRPC and GraphQL):
Add Sufficient Details in Error Message
Error messages should contain sufficient information that a developer or consuming client can act upon.
{ "errorMessage": "An error has occurred." }Figure: Bad example - The error message does not contain information that can be acted upon
{ "errorMessage": "Client ID is a required field. Please provide a Client ID." }Figure: Good example - The error message provides explicit detail and a short description on how to fix the issue
Sanitize Response
HTTP/1.1 500 Internal Server Error Transfer-Encoding: chunked Content-Type: text/plain Server: Microsoft-IIS/10.0 X-Powered-By: ASP.NET Date: Fri, 27 Sep 2019 16:13:16 GMT System.ArgumentException: We don't offer a weather forecast for chicago. (Parameter 'city') at WebApiSample.Controllers.WeatherForecastController.Get(String city) in C:\working_folder\aspnet\AspNetCore.Docs\aspnetcore\web-api\handle-errors\samples\3.x\Controllers\WeatherForecastController.cs:line 34 at lambda_method(Closure , Object , Object[] ) at Microsoft.Extensions.Internal.ObjectMethodExecutor.Execute(Object target, Object[] parameters) at Microsoft.AspNetCore.Mvc.Infrastructure.ActionMethodExecutor.SyncObjectResultExecutor.Execute(IActionResultTypeMapper mapper, ObjectMethodExecutor executor, Object controller, Object[] arguments) at Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker.<InvokeActionMethodAsync>g__Logged|12_1(ControllerActionInvoker invoker) at Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker.<InvokeNextActionFilterAsync>g__Awaited|10_0(ControllerActionInvoker invoker, Task lastTask, State next, Scope scope, Object state, Boolean isCompleted) at Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker.Rethrow(ActionExecutedContextSealed context) at Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker.Next(State& next, Scope& scope, Object& state, Boolean& isCompleted) at Microsoft.AspNetCore.Mvc.Infrastructure.ControllerActionInvoker.InvokeInnerFilterAsync() --- End of stack trace from previous location where exception was thrown --- at Microsoft.AspNetCore.Mvc.Infrastructure.ResourceInvoker.<InvokeFilterPipelineAsync>g__Awaited|19_0(ResourceInvoker invoker, Task lastTask, State next, Scope scope, Object state, Boolean isCompleted) at Microsoft.AspNetCore.Mvc.Infrastructure.ResourceInvoker.<InvokeAsync>g__Logged|17_1(ResourceInvoker invoker) at Microsoft.AspNetCore.Routing.EndpointMiddleware.<Invoke>g__AwaitRequestTask|6_0(Endpoint endpoint, Task requestTask, ILogger logger) at Microsoft.AspNetCore.Authorization.AuthorizationMiddleware.Invoke(HttpContext context) at Microsoft.AspNetCore.Diagnostics.DeveloperExceptionPageMiddleware.Invoke(HttpContext context) HEADERS ======= Accept: */* Host: localhost:44312 User-Agent: curl/7.55.1Figure: Bad example - this level of data should not be returned in a production environment
Provide a Tracking or Correlation ID
A tracking or correlation ID will allow the consuming clients to provide the API developers with a reference point in their logs.
{ "errorMessage": "An error has occurred. Please contact technical support" }Figure: Bad example - No tracking or correlation ID is provided
{ "errorMessage": "An error has occurred. Please contact technical support", "errorId": "3022af02-482e-4c06-885a-81d811ce9b34" }Figure: Good exmaple - A error ID is provided as part of the reponse
Provide an additional Help Resource
Providing a URI to an additional help resources as part of your request will allow consuming clients to find additional resources or documentation that relates to the defined problem.
{ "ErrorType": "DoesNotExist", "Id": "3022af02-482e-4c06-885a-81d811ce9b34", "Message": "No Client with a ID of 999999999 was found", "StatusCode": 404 }Figure: Bad example - No help link provided
{ "ErrorType": "DoesNotExist", "HelpLink": "http://www.myapiapplication/api/help/doesnotexist", "Id": "3022af02-482e-4c06-885a-81d811ce9b34", "Message": "No Client with a ID of 999999999 was found", "StatusCode": 404 }Figure: Good example - A help link is provided as part of the response
-
The use of correct response codes is a simple yet crucial step towards building a better WebAPI. In ASP.NET Core, by default the WebAPI framework sets the response status code to 200 (OK), regardless of whether the task succeed or an error occurred.
You can save yourself countless hours of painful debugging , by specifying the correct response code.
For example: According to the HTTP/1.1 protocol, when a POST request results in the creation of a resource, the server should reply with status 201 (Created).
public Product PostProduct(Product item) { item = repository.Add(item); return item; }Figure: Bad Example – By default a 200 status code is returned.
[ResponseType(typeof(CreditSnapshot))] public HttpResponseMessage PostProduct(Product item) { item = repository.Add(item); var response = Request.CreateResponse(HttpStatusCode.Created, item); return response; }Figure: Good Example – When creating objects the “Created” status code is returned.
public void PutProduct(int id, Product product) { product.Id = id; if (!repository.Update(product)) { return Request.CreateResponse(HttpStatusCode.NotFound, ex.Message); } }Figure: Good Example – When updating or deleting objects, if the object to be modified cannot be found throw exception with HttpStatusCode.NotFound
Client-side validation provides a great user experience but this must always be backed up by server-side validation.

Figure: Client-side validation does not provide effective data security for your Web API endpoints .NET and .NET Core Web APIs provide built-in support for validation using Data Annotations:
- Decorate your model classes with validation attributes, e.g. [Required], [MaxLength(60)]
- The MVC data binding system will automatically validate all entities sent to a controller and set ModelState.IsValid and ModelState.Values / Errors
- As per Do you apply the ValidateModel attribute to all controllers? you can create an attribute to apply this validation to all your Web API endpoints
Fluent Validation improves the built-in capabilities in a number of ways:
- It is outside of your ApiController, so can be shared with other API protocols (like GraphQL or gRPC).
- It plugs directly into the existing data binding and validation engine (as above) so you can adopt Fluent Validation without changing the client-side
- It is also easy to apply Fluent Validation to inner layers of your application
- You can specify multiple rulesets for a model without modifying the model itself
- Fluent validation uses a powerful Fluent API with LINQ expressions
using FluentValidation; public class CustomerValidator: AbstractValidator<Customer> { public CustomerValidator() { RuleFor(x => x.Surname).NotEmpty(); RuleFor(x => x.Forename).NotEmpty().WithMessage("Please specify a first name"); RuleFor(x => x.Discount).NotEqual(0).When(x => x.HasDiscount); RuleFor(x => x.Address).Length(20, 250); RuleFor(x => x.Postcode).Must(BeAValidPostcode).WithMessage("Please specify a valid postcode"); } private bool BeAValidPostcode(string postcode) { // custom postcode validating logic goes here } }Good example: Fluent Validation uses LINQ expressions allowing the development of powerful, type-checked rulesets without needing to modify the class under validation.
- You can write conditional rules with the .When clause. This is great for complex form validation.
RuleFor(x => x.Discount).NotEqual(0).When(x => x.HasDiscount);Good Example: Conditional validation with the .When() clause allows for complex logic such as “Discount number cannot be 0 if the HasDiscount boolean is true”
- Fluent Validation provides a great entry-point for writing your own custom, complex rules. For most modern Web APIs the response type is usually JSON. The validation errors raised by Fluent Validation serialize easily to JSON making it fairly trivial to handle these errors from whatever client-side framework you are using.
{ "CompanyName": [ "The CompanyName field is required." ] }Good Example: This is the JSON returned from Fluent Validation when a validation rule fails. This is exactly the same format as what would be returned by the built-in ModelState validation.