Rules to Better SQL Databases - Developers - 64 Rules
Here are some of the typical things that all SQL Server DBAs and Database developers should know. These rules are above and beyond the most basic textbook recommendations of:
- Ensuring your databases are Normalized and in 3rd Normal Form
- Making sure you have primary keys, foreign keys and simple indexes to improve performance
- Making sure you Back up regularly
- Basic Naming conventions (see some of our object naming conventions)
- Minimizing result set sizes and data over the wire
View Database Coding Standard and Guideline.
Want to develop your SQL Server Database with SSW? Check SSW's Databases consulting page.
Imagine an e-commerce company called Northwind Traders, where thousands of products, multiple sellers, and millions of customers converge. In such a company, the importance of a well-designed database cannot be overstated. Consider the scenario where a customer places an order only to encounter delays and frustration due to data inconsistencies that wrongly indicate an out-of-stock product. To mitigate such chaos, developers rely on relational database design principles, including normalization and entity-relationship diagrams (ERDs). These concepts provide the foundation for a well-structured database with improved data integrity and reduced redundancy, ensuring smooth operations and customer satisfaction.
Poor database design - The problems
If a database lacks proper structure and organization, many problems can arise. These include:
- Data Duplication e.g. If Northwind Traders employee details, like home address, are stored separately in the HR and Payroll departments, an update in one place may not reflect in the other, leading to inconsistencies.
- Update Anomalies e.g. If a customer's phone number is stored in multiple places in the database, a change in contact information might not be updated everywhere, causing confusion when attempting to reach them.
- Insertion Anomalies e.g. If a database requires a vendor's details when adding a new product, it would be difficult to add a new product if the vendor information isn't available at the time of entry.
- Deletion Anomalies e.g. If a customer record is deleted from the database, it might unintentionally delete all associated order records, erasing valuable sales data.
The Solution
Solving these problems is hard. Luckily, there are some tried and tested tools that help resolve these problems including:
Database normalization and ERDs are the core tools needed to perform good relational database design. If these concepts are misapplied or are not used at all, there can be disastrous consequences with far-reaching effects. For example, once you start putting data into a table, it becomes significantly harder to fix since you now have a data migration problem. That's why getting database design right the first time is vital.
Database Normalization is a systematic approach to designing databases that reduces redundancy and avoids potential anomalies during data update, deletion, or insertion. This process involves organizing the columns (attributes) and tables (relations) of a database to ensure their dependencies are properly enforced by database integrity constraints.
Normalization is typically carried out through a series of steps called normal forms, each with specific rules:
- First Normal Form (1NF)
- Second Normal Form (2NF)
- Third Normal Form (3NF)
There are further normal forms, and the theory constantly evolves, but these 3 are the bare minimum required for database design.
Video: Database normalization explained
Normal forms explained - the example of a library checkout system
Consider a library checkout system where each row in the table represents a book-borrowing transaction.
We might start with an unnormalized data set that looks like this:
Transaction table
BorrowerName Books John Doe "1984, Harry Potter" Sarah Smith "To Kill a Mockingbird, The Catcher in the Rye" John Doe "Moby Dick", "Pride and Prejudice" 1st Normal Form (1NF)
1st normal form means ensuring:
- Each record is unique
- Each table cell contains a single value
- All values are atomic - meaning no values can be split into smaller parts
Ensuring each record is unique
The first thing to do is make sure each record is unique. We can assign a unique transaction identifier for each book borrowing transaction.
Transaction table
TransactionID BorrowerName Books 1 John Doe "1984, Harry Potter" 2 Sarah Smith "To Kill a Mockingbird, The Catcher in the Rye" 3 John Doe "Moby Dick", "Pride and Prejudice" Ensuring each cell contains a single value
Next, the cells in the table need to contain only 1 value. This concept can be applied by breaking up the "Books" field so that each cell contains a single value.
Transaction table
TransactionID BorrowerName Book 1 John Doe "1984" 2 John Doe "Harry Potter" 3 Sarah Smith "To Kill a Mockingbird" 4 Sarah Smith "The Catcher in the Rye" 5 John Doe "Moby Dick" 6 John Doe "Pride and Prejudice" Ensuring all values are atomic
Lastly, all values must be atomic to ensure that the data is in the smallest form possible without losing its meaning. For example, in the Transaction table, the "BorrowerName" field can be split into "FirstName" and "LastName", however the "Book" cannot because "To Kill" and "a Mockingbird" would not make sense separately.
Transaction table
TransactionID FirstName LastName Book 1 John Doe "1984" 2 John Doe "Harry Potter" 3 Sarah Smith "To Kill a Mockingbird" 4 Sarah Smith "The Catcher in the Rye" 5 John Doe "Moby Dick" 6 John Doe "Pride and Prejudice" Now the table is in 1st Normal Form (1NF). It has unique records, each cell contains a single value, and all values are atomic.
2nd Normal Form (2NF)
2nd normal form means ensuring:
- Database is already in 1NF
- Every non-primary key attribute is fully functionally dependent on all parts of the primary key
Let's examine the data to see how we can change it into 2NF:
- FirstName and LastName don't change based on TransactionID, meaning they aren't functionally dependent on TransactionID. For example, John Doe could borrow books 10 times, but his name would always stay the same.
- Book can change for each TransactionID, so it functionally depends on TransactionID. For example, John Doe could borrow different books in all 10 transactions.
Therefore we need to split FirstName and LastName into a new table. Since that table identifies the person borrowing the books, we could call it "Borrower". We also need to introduce a BorrowerID to ensure it is uniquely identified as per 1NF.
Transaction table
TransactionID BorrowerID Book 1 1 "1984" 2 1 "Harry Potter" 3 2 "To Kill a Mockingbird" 4 2 "The Catcher in the Rye" 5 1 "Moby Dick" 6 1 "Pride and Prejudice" Borrower table
BorrowerID FirstName LastName 1 John Doe 2 Sarah Smith 3rd Normal Form (3NF)
3rd normal form means ensuring:
- Database is already in 2NF
- Every non-primary key attribute directly depends on the primary key, not any other non-key attribute
Let's imagine that we wanted to introduce a genre to the table. Our data might look like this:
Transaction table
TransactionID BorrowerID Book Genre 1 1 "1984" Dystopian 2 1 "Harry Potter" Fantasy 3 2 "To Kill a Mockingbird" Historical Fiction 4 2 "The Catcher in the Rye" Coming-of-Age 5 1 "Moby Dick" Romance 6 1 "Pride and Prejudice" Adventure It looks ok here, but what if John decided to borrow "To Kill a Mockingbird"? The Genre would be repeated as follows:
Transaction table
TransactionID BorrowerID Book Genre 1 1 "1984" Dystopian 2 1 "Harry Potter" Fantasy 3 2 "To Kill a Mockingbird" Historical Fiction 4 2 "The Catcher in the Rye" Coming-of-Age 5 1 "Moby Dick" Romance 6 1 "Pride and Prejudice" Adventure 7 1 "To Kill a Mockingbird" Historical Fiction So to fix it, Book needs to become a separate table.
Transaction table
TransactionID BorrowerID BookID 1 1 1 2 1 2 3 2 3 4 2 4 5 1 6 6 1 5 7 1 3 Book table
BookID Book Genre 1 "1984" Dystopian 2 "Harry Potter" Fantasy 3 "To Kill a Mockingbird" Historical Fiction 4 "The Catcher in the Rye" Coming-of-Age 5 "Pride and Prejudice" Romance 6 "Moby Dick" Adventure Summary
Database Normalization is a method of ensuring a relational database conforms to good design principles. Normal Forms are definitions for different levels as you progress through normalization.
The use of these tools helps improve data integrity and reduce data redundancy.
Further Study
- Microsoft Office's Troubleshoot Access Database Normalization Description: https://learn.microsoft.com/en-us/office/troubleshoot/access/database-normalization-description
Relational databases are complicated, and understanding the entire architecture of a database can be difficult when expressed solely in words. That's where Entity Relationship Diagrams (ERDs) come in. ERDs are a way of visualizing the relationships between different entities and their cardinality.
Video: ERDs explained
Cardinality
Cardinality is a crucial concept within entity relationship modeling which refers to the number of instances of an entity that can be associated with each instance of another entity. Defining cardinality helps people understand the nature of relationships.
The cardinality of relationships can be one-to-one, one-to-many, or many-to-many.
-
One-to-One: Each instance of entity A can be associated with one instance of entity B, and vice versa.
- e.g. each employee in a company has one employee ID, and each employee ID is associated with one employee.
-
One-to-Many: Each instance of entity A can be associated with multiple instances of entity B, but each instance of entity B is associated with only one instance of entity A.
- e.g. one author can write many books, but each book is written by one author.
-
Many-to-Many: Each instance of entity A can be associated with multiple instances of entity B, and vice versa.
- e.g. a student can enrol in multiple courses, and multiple students can take a course.
Optionality
In addition to the above relationship types, each side of the relationship may be optional. Let's examine the case of an airline company which tracks Pilots and Completed Flights.
- 1 Flight must always have at least one Pilot
- 1 Pilot can have 0, 1 or many Flights (they may have 0 if they have been recently hired)
So in this case, the Pilot having Flights is optional.
Handling Many-to-Many - Practical Example - Student Courses
Many-to-many relationships require special handling to ensure that the relationships and their data can be stored accurately in the database. An associative entity (also known as a joining table) handles this by converting the many-to-many relationship into two one-to-many relationships.
Let's imagine a university that wants to track students and courses. In this example, 1 student has many courses, and 1 course has many students, meaning it has a many-to-many relationship.
❌ Bad Example - Architecting the schema to have 1 table
The bad way to architect the schema for this scenario is using a single table. This method results in lots of repeated data.
StudentCourses Table
FirstName LastName CourseName Instructor Alice Smith Math Prof. Smith Alice Smith English Prof. Johnson Bob Northwind Math Prof. Smith ✅ Good Example - Architecting the schema to have 3 tables
A better way to architect the schema for this scenario is to break it into 3 tables with 2 relationships. Now the data is properly normalized and we can track which students do which courses, and any extra details such as when the student starts the course.
Students Table
Contains the student data
StudentID Name LastName 1 Alice Smith 2 Bob Northwind Courses Table
Contains the course data
CourseID CourseName Instructor 1 Math Prof. Smith 2 English Prof. Johnson StudentCourses Table
Contains the data about which students are taking which courses
StudentID CourseID 1 1 1 2 2 1 Relationship 1 - Students and StudentCourses
- 1 Student has many StudentCourses
- 1 StudentCourse has 1 Student
Relationship 1 - Courses and StudentCourses
- 1 Course has many StudentCourses
- 1 StudentCourse has 1 Course
Visualization
Note how wordy it was to illustrate the many-to-many relationship in the StudentCourses example. Now imagine that database expands to have 10 more tables. It would quickly become hard to keep track of everything. This problem is what ERDs solve.
An ERD helps quickly display all the relationships in a database at a glance. Let's see what it looks like for StudentCourses:

Figure: Student Courses ERD In this example, Students, Courses and StudentCourses are represented via the rectangles. Meanwhile, their relationships are shown via the lines between the rectangles. You can see the cardinality indicated by what is called Crow's foot notation.
Summary
ERDs are a fantastic tool for visualizing a database at a glance. Through using this tool, developers can ensure they have a solid understanding of how data in the database is related and identify any problems quickly and easily.
Further Study
- Lucidchart's ER Diagrams page: https://www.lucidchart.com/pages/er-diagrams
-
NULLs complicate your life. To avoid having to constantly differentiate between empty strings and NULLs, you should avoid storing NULLS if you can.Why? Well, what is wrong with this?
SELECT ContactName FROM Customer WHERE ContactName <> ''Figure: Selecting on empty string
Nothing if your data is perfect, but if you allow Nulls in your database, then statements like this will give you unexpected results. To get it working you would have to add the following to the last line:
WHERE ContactName <> '' OR ContactName Is NullFigure: Allowing null strings makes queries more complex
What about only allowing empty strings? Well, we choose to block Nulls because it is a lot easier to check off a check box in SQL Server Management Studio than it is to put a constraint on every field that disallows empty string ('').
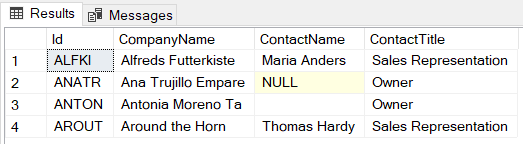
Figure: Don't allow Nulls However, you should always be aware that Nulls and empty strings are totally different, so if you absolutely have to have them, they should be used consistently. In the ANSI SQL-92 standard, an empty string ('') is never equated to Null, because empty string can be significant in certain applications.
Not allowing Nulls will give you the following benefits:
- Don't have to enforce every text field with a CHECK constraint such as ([ContactName]<>'').
- Make your query simpler, avoid extra checking in stored procedures. So you don't have to check for NULLs and empty strings in your WHERE clause.
- SQL Server performs better when nulls are not being used.
- Don't have to deal with the pain in the middle tier to explicitly check DBNull.Value, you can always use contactRow.ContactName == String.Empty. Database Nulls in the .NET framework are represented as DBNull.Value and it cannot implicitly typecast to ANY other type, so if you are allowing NULLs in ContactName field, the above comparing will raise an exception.
- Avoid other nasty issues, a lot of controls in the .NET framework have real problems binding to DBNull.Value. So you don't have write custom controls to handle this small thing.
For example, you have Address1 and Address2 in your database, a Null value in Address2 means you don't know what the Address2 is, but an empty string means you know there is no data for Address2. You have to use a checkbox on the UI to explicitly distinguish Null value and empty string:
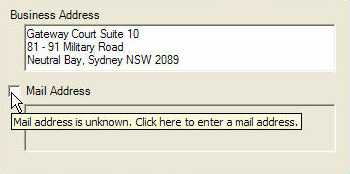
Figure: A check box is required if you want to allow user to use Null value on the UI Some people are not going to like this rule, but this is how it works in Oracle and Access:
- In Oracle, empty strings are turned into Nulls (which is basically what this rule is doing). Empty strings per se are not supported in Oracle (This is not ANSI compliant).
- And talking of legacy systems :-) be aware that using Access as a data editor is a "No-No". Access turns empty strings into a Null.
Finally, always listen to the client, Nulls have meaning over an empty string - there are exceptions where you might use them - but they are rare.
So follow this rule, block Nulls where possible, update your NULLs with proper information as soon as possible, and keep data consistent and queries simple.
NULLs create difficulty in the middle-tier because you need to add further handling. So avoid them where you can, eg. For a Discount field, make the default 0 and don't allow NULLs.
This rule should not be applied when a NULL value is valid data. Often times data such as a percent earnings rate on a super fund is nullable because it may not be supplied or relevant. This is very different to it being zero and you have no way to determine real zero values from not supplied data. The hit of doing the work in code is often offset in this case by the validity of query results.
As a general rule of thumb, don't use NULL if you cannot distinguish it from another value.
Q: What is the difference between NULL and 0 in the field "Discount"? A: No difference, so don't allow NULL.
Q: What is the difference between NULL and 0 in the field "DailySugarIntake"? A: NULL means unknown and 0 means no daily sugar intake, so allow NULL.
Note: Nulls are evil, but don't go crazy removing nulls. Never invent your own constant eg. -999 to represent a Null.
Text in character columns (char, varchar, text, nchar, varchar, text) can start with spaces or empty lines which is usually data entry error.
The best way to avoid this issue is to handle whitespace in the middle-tier before it reaches the database.
Here’s an example of removing whitespace and carriage returns in the middle-tier using Regex:
static string Trim(string inputText) { Match m = Regex.Match(inputText, @"[^\s]"); return m.Success ? inputText.Substring(m.Index) : inputText; }Figure: C# Removing whitespace and carriage returns in middle-tier
The code above:
- Uses Regular Expressions (Regex) to match the first non-whitespace character (includes tabs, spaces, line feeds and carriage returns).
- Retrieves the index of the character
- Returns the text from the character onwards, thus removing the whitespace at the start
This code could be triggered in the middle-tier before inserting into the database.
This one is going to be a controversial one. But the bottom line is every now and then you want to do something and then you curse and wish your database didn't have identities. So why use them? Let's look at the problems first:
Cons
- You can't manually change a Primary Key and let the Cascade Update do its work, eg. an InvoiceID
- Hassles when importing data into related tables where you want to control the Primary Key eg. Order and Order Details
- Replication you will get conflicts
In Microsoft Access you have autonumbers and there is no way around them so never use them.But in SQL Server you have identities and we have these procs:
- DBCC CHECKIDENT - Checks the current identity value for the specified table and, if needed, corrects the identity value
- SET IDENTITY_INSERT { table } { ON | OFF } - Allows explicit values to be inserted into the identity column of a table
Pros
- Less programming - letting the database take care of it
- Replication (identities are supported by SQL Server with ranges so when you want replication, no coding)
- Avoiding concurrency errors on high INSERT systems so no coding
So the only Con left is the importing of data but we can use one of the above procs to get around it. See grey box.
The best way to import data into SQL Server (with Identities)
Using SQL Management Studio
- Right-Click your database to open the menu
- Navigate to Tasks | Import Data… to open the wizard
- When selecting Source Tables and Views click on Edit Mappings…
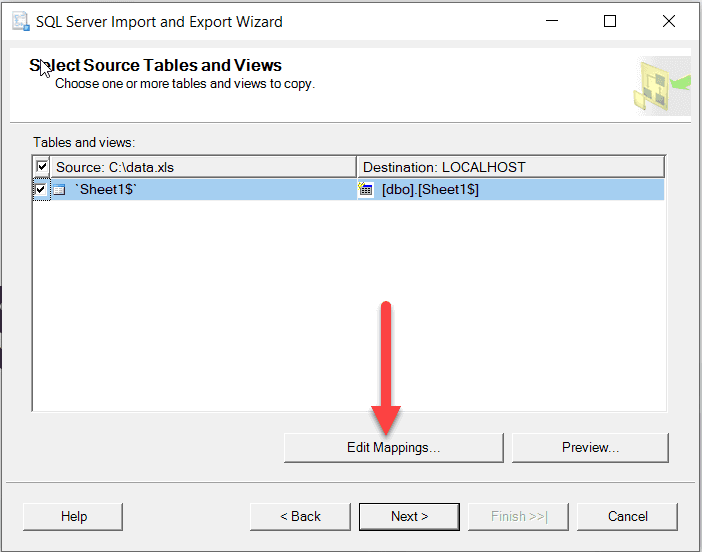
Figure: SQL Import Wizard - Edit Mappings - Ensure the Enable identity insert is checked
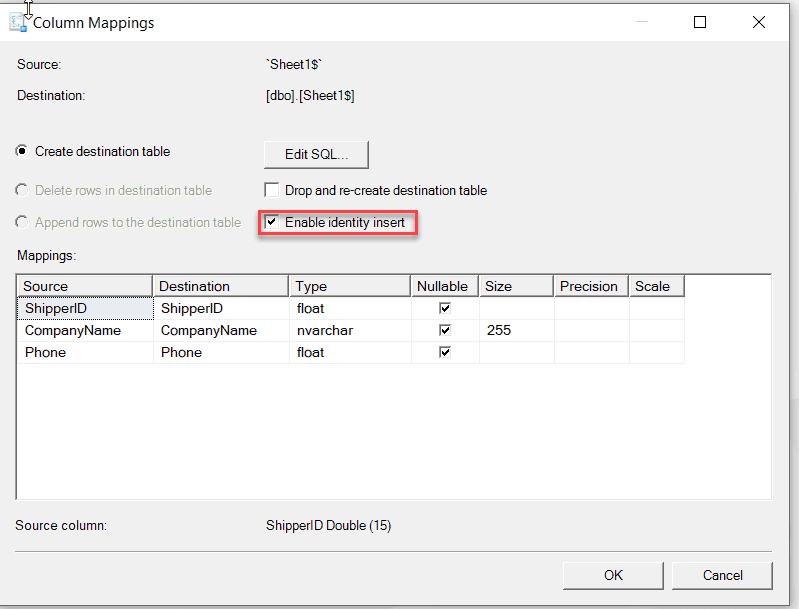
Figure: SQL Import Wizard – Ensure Enable identity insert is checked
Alternatively, you can also enable and disable the identity insert through SQL with the following commands:
SET IDENTITY_INSERT Shippers ON --this will allow manual identity INSERTS on the requested table -- Modify the table here SET IDENTITY_INSERT Shippers OFF --as it can only be on for one table at a timeMore information on IDENTITY_INSERT
Automatic Identity Range Handling
The simplest way of handling identity ranges across replicas is to allow SQL Server to manage identity range handling for you. To use automatic identity range handling, you must first enable the feature at the time the publication is created, assign a set of initial Publisher and Subscriber identity range values, and then assign a threshold value that determines when a new identity range is created.For example, assigning an identity range from 1000 through 2000 to a Publisher, and a range from 2001 through 3000 to an initial Subscriber a range from 3001 to 4000 to the next publisher etc.
When users are deleting a lot of records as part of normal operations - they can and do make mistakes. Instead of the painful process of having to go to a backup to get these records, why not simply flag the records as IsDeleted?
Advantages
- You do not have to delete all related records e.g. Customers, Orders, Order Details. Instead, you can just flag the parent record as deleted with an "IsDeleted" bit field.
- You do not lose historical data e.g. how many products one of your previous clients purchased.
- You can actually see who deleted the record, as your standard audit columns (e.g. DateUpdated, UserUpdated are still there. The record does not just vanish.
Disadvantages
- Depending on your interface design, you may have to join to parent tables to ensure that deleted child records do not appear. Typically, the interface would be designed in such a way that you would not need be able to created new records based on the deleted items (e.g. you cannot create a new order record for a customer that is deleted). Performance of queries can potentially suffer if you have to do these joins.
- While storage space is very cheap, you are not removing records from your database. You may need to archive records if the number of deleted records becomes large.
Best Approach for Implementing Soft Delete in EF Core for modern web application.
1.
ISoftDeleteEntityInterfaceImplement an interface
IsSoftDeleteEntitywith a boolean propertyIsDeleted,Entities requiring soft delete should implement this interface.public interface ISoftDeleteEntity { bool IsDeleted { get; set; } }2. Global Query Filters
Apply global query filters to automatically exclude soft-deleted entities:
modelBuilder.Entity<MyEntity>().HasQueryFilter(e => !e.IsDeleted);This ensures queries do not return entities marked as deleted automatically eliminating the need to add an extra where condition in the actual queries.
3. EF Core Interceptors for Soft Delete
Override the default delete behavior using EF Core interceptors by using an interceptor. This changes entity state to
Modifiedand setsIsDeletedtotrueinstead of completely removing the record.public class SoftDeleteInterceptor : SaveChangesInterceptor { public override InterceptionResult<int> SavingChanges(DbContextEventData eventData, InterceptionResult<int> result) { foreach (var entry in eventData.Context.ChangeTracker.Entries<ISoftDeleteEntity>()) { if (entry.State == EntityState.Deleted) { entry.Entity.IsDeleted = true; entry.State = EntityState.Modified; } } return base.SavingChanges(eventData, result); } }Note: Make sure the entites that require soft delete has implemented the ISoftDeleteEntity interface for them to be captured into this interceptor.
4. Registering the Interceptor
Register the custom interceptor in the
DbContextconfiguration:services.AddDbContext<MyDbContext>(options => options.UseSqlServer(connectionString) .AddInterceptors(new SoftDeleteInterceptor()));This integrates the interceptor with the EF Core context, this will ensure to run the entity through this interceptor every time context.saveChanges() is triggered.
Also see Using Audit Tools for alternatives to this approach using 3rd party auditing tools. ::: greybox
Watch William Liebenberg's SpendOps talk for more details about why soft deletes are advantageous in Azure:
- SSW TV video: Real-life SpendOps with Azure Cosmos DB
- NDC video: Azure SpendOps – The Art of Effectively Managing Azure Costs
:::
SQL Server dates can range from the year 1900 up to the year 9999. However, certain date data in your database just wouldn't make any sense in the context of your business. For example, if your company started trading in 2015 you should not have any dates in your database before 2015 (unless you are tracking start dates of your clients, but this is an exception). An invoice date of 2013 wouldn't make sense at all.
There are two methods to avoid this:
-
Using Validation Queries
You can run validation queries to ensure no rubbish date data gets into your database.
-
Using Constraints
Alternatively, you can use Constraints to limit the date range from your own earliest specified date.
Here’s an example of implementing a date range constraint.
CONSTRAINT chk_INVOICE_DATE CHECK (INVOICE_DATE > TO_DATE('2015-01-01', 'yyyy-mm-dd'))-
Any DateTime fields must be converted to universal time from the application to the stored procedures when storing data into the database.
We can simplify dealing with datetime conversions by using a date and time API such as Noda TIme.
Noda Time uses the concept of an Instant representing a global point in time, which is first converted to UTC time and then to the users local time when required for display.An Instant is the number of nanoseconds since January 1st 1970. Using an Instant gives more granularity than datetime because it uses nanoseconds rather than ticks (100 nanoseconds).
//------ .NET DateTime Examples int year, month, day; int hour, minute, second; long nowInTicks = DateTime.Now.Ticks; // 637158251390332189 DateTime now = DateTime.Now; DateTime nowUtc = DateTime.UtcNow; DateTime date = new DateTime(2020, 1, 2); // 2/01/2020 12:00:00 AM TimeSpan time = new TimeSpan(16, 20, 0); // 16:20:00 DateTime dateTime = date + time; // 2/01/2020 4:20:00 PM date = dateTime.Date; time = dateTime.TimeOfDay; year = date.Year; month = date.Month; day = date.Day; hour = time.Hours; minute = time.Minutes; second = time.Seconds; int startDate = (int)date.DayOfWeek; int target = (int)DayOfWeek.Wednesday; if (target <= startDate) target += 7; DateTime nextWednesday = date.AddDays(target - startDate); // 8/01/2020 12:00:00 AM startDate = (int)date.DayOfWeek; target = (int)DayOfWeek.Friday; if (target > startDate) target -= 7; DateTime lastFriday = date.AddDays(-(startDate - target)); // 27/12/2019 12:00:00 AM TimeSpan t1 = TimeSpan.FromDays(1.0); TimeSpan t2 = TimeSpan.FromHours(1.0); int timespanCheck = TimeSpan.Compare(t1, t2); TimeSpan longestSpan; TimeSpan shortestSpan; if(timespanCheck > 0) { longestSpan = t1; shortestSpan = t2; } else if(timespanCheck < 0) { shortestSpan = t1; longestSpan = t2; }Figure: Bad example - Using .NET DateTime to manipulate dates and times
//------ Noda Time Examples int year, month, day; int hour, minute, second; Instant nowAsInstant = SystemClock.Instance.GetCurrentInstant(); // 2020-01-28T05:18:26Z DateTimeZone zone = DateTimeZoneProviders.Tzdb["Australia/Melbourne"]; ZonedClock utcClock = SystemClock.Instance.InUtc(); ZonedClock localClock = SystemClock.Instance.InZone(zone); LocalDate ntDate = new LocalDate(2020, 1, 2); // Thursday, 2 January 2020 LocalTime ntTime = new LocalTime(16, 20); // 4:20:00 PM LocalDateTime ntdateTime = ntDate.At(ntTime); // 2/01/2020 4:20:00 PM ntdateTime.Deconstruct(out ntDate, out ntTime); ntDate.Deconstruct(out year, out month, out day); ntTime.Deconstruct(out hour, out minute, out second); LocalDate ntNextWednesday = ntDate.Next(IsoDayOfWeek.Wednesday); // Wednesday, 8 January 2020 LocalDate ntLastFriday = ntDate.Previous(IsoDayOfWeek.Friday); // Friday, 27 December 2019 Duration d1 = Duration.FromDays(1); Duration d2 = Duration.FromHours(1); Duration longestDuration = Duration.Max(d1, d2); Duration shortestDuration = Duration.Min(d1, d2);Figure: Good example - Using Noda Time to manipulate dates and times
When retrieving data from the database it must be converted back to the local time of the user.
That way you get an accurate representation of the time someone entered data into the database (i.e. the DateUpdated field).The exception to this rule, however, is for already existing databases that deal with DateTime as part of their queries.e.g. SSW TimePro is an application that allows employees to enter their timesheet.The table used for storing this information has an important field that has a DateTime data type.
This cannot be converted to UTC in the database because that would mean:
- Converting every single entry since entries began being stored (in SSW's case since 1996) to keep information consistent;
- Other separate applications currently using the timesheet information in the database for reporting will also have to be entirely modified.
Currently, there will be an issue if for example, someone from the US (Pacific time) has 19 hours difference between their local time and our servers.
Example: Sally in the US enters a timesheet for the 21/04/05. (which will default to have a time of 12:00:00 AM since the time was not specified) Our servers will store it as 21/04/05 19:00:00 in other words 21/04/05 07:00:00 PM because the .NET Framework will automatically convert the time accordingly for our Web Service. Therefore our servers have to take the Date component of the DateTime and add the Time component as 12:00:00 AM to make it stored in our local time format.
[WebMethod] public double GetDateDifference(DateTime dateRemote) { DateTime dateLocal = dateRemote.Date; return (dateRemote.TimeOfDay.TotalHours - dateLocal.TimeOfDay.TotalHours); }Figure: When dateRemote is passed in from the remote machine, .NET Framework will have already converted it to the UTC equivalent for the local server (i.e. the necessary hours would have been added to cater for the local server time)
In the above code snippet, the .Date property would cut off the Time portion of the DateTime variable and set the Time portion to "12:00:00 AM" as default.
This is for applications we currently have that:
- Consider the DateTime component integral for the implementation of the application.
- Will be used world-wide.
In many cases, there are legal requirements to audit all updates to financial records. In other cases, you will want to be able to track and undo deletes to your database. With the use of Temporal tables, this becomes much easier to manage.
Temporal tables were introduced in SQL Server 2016 and enhanced with increased features in SQL Server 2017. They offer the ability to record all the entity changes to a history table allowing the querying of the entity at a point in time.
Pros:
- You can query values of a specific entity at a particular point in time or time range over its lifetime.
- Restore accidentally deleted records by retrieving them from the history table.
- Retention period can be set on the history table, this can be set as frequent as 1 day.
Cons:
- History tables can grow very quickly in size.
- Storing blob datatypes (nvarchar(max), varbinary(max), ntext and image) can increase storage costs and decrease performance.
- You cannot truncate the table.
- Temporal and history table cannot be FILETABLE.
- Direct modification of the data in the history is not permitted.
How do I create a Temporal table?
It’s actually quite simple, here is a code snippet converting a table from the Northwind schema into a temporal table.
CREATE TABLE dbo.Shippers ( [ShipperID] int IDENTITY(1, 1) NOT NULL, [CompanyName] nvarchar(40) NOT NULL, [Phone] nvarchar(24) NULL, [SysStartTime] datetime2 GENERATED ALWAYS AS ROW START, [SysEndTime] datetime2 GENERATED ALWAYS AS ROW END, PERIOD FOR SYSTEM_TIME (SysStartTime, SysEndTime), CONSTRAINT PK_Shippers PRIMARY KEY CLUSTERED ( [ShipperID] ) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ShippersHistory));Figure: Shippers table from the Northwind schema converted to a temporal table.
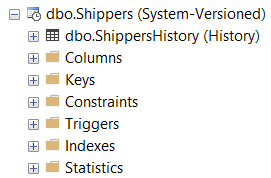
Figure: New temporal table shown in SQL Management Studio. -- Update the tables history data retention ALTER TABLE dbo.Shippers SET (SYSTEM_VERSIONING = ON (HISTORY_RETENTION_PERIOD = 7 YEARS));**Figure: Code snippet for updating data retention.**
Some alternative solutions are:
- Manually adding triggers on all database tables to log every table
- The business objects or stored procedures all write to 2 tables the main table such as Customer and CustomerAudit
- Using a logging utility to audit database changes
This means that you can devote your development time to areas other than auditing. Also, unlike other utilities which use triggers (such as ApexSQL Audit), there is no performance overhead because it relies upon log files already created by SQL Server. If required, you can export the log information to SQL Server, so you can perform advanced queries on it. It even allows you to recover previously deleted tables.
We believe it is not good that use invalid characters (most of are Symbol characters, like ",;"/(", etc.) in object identifiers. Though it is legal, it is easily confused and probably cause an error during run script on these objects.
It is common to have a Contact Detail table to store your contact information such as phone numbers. Below is an example of a Contact Detail table and its related tables. This is bad because the PartyPhone table is too specific for a phone number and you have to add a new table to save an email or other contact information if this is needed in the future.
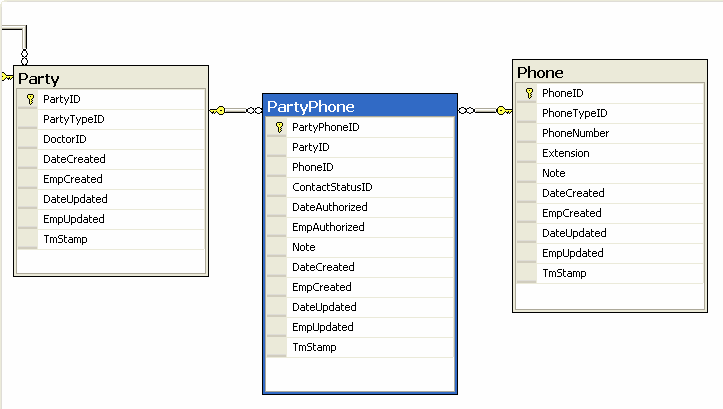
Figure: Bad Example - A too specific Contact Detail table We normally have a general Contact Detail table that includes all the different categories of phone numbers, whether it is shared or primary plus emails all in the same table.
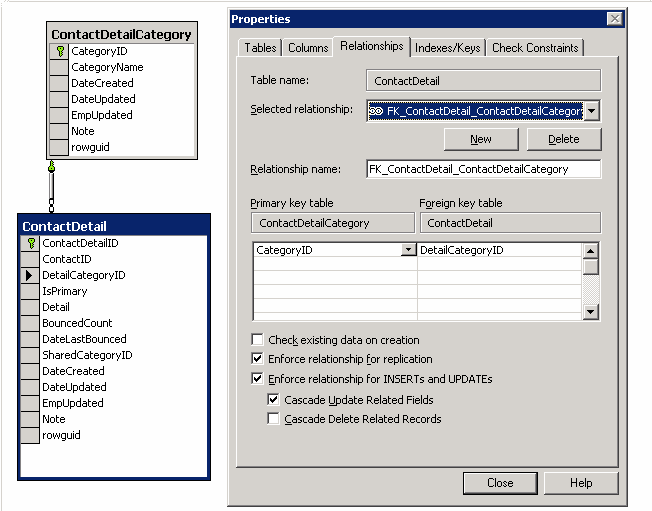
Figure: Good Example - A general Contact Detail table We use a Contact Detail Category table to store these categories.
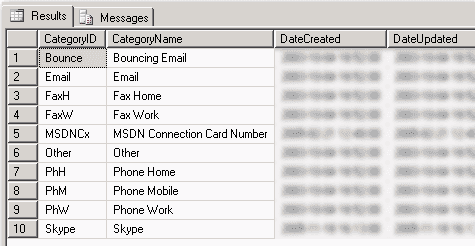
Figure: Good Example - Details of Contact Detail Category table We recommend that you use a URL instead of an image in your database, this will make you:
- Avoid the size of your database increasing too quickly (which may bring a serial of problems, like performance, log and disk space, etc);
- Easy to validate and change the image.
Columns defined using the nchar and nvarchar datatypes can store any character defined by the Unicode Standard, which includes all of the characters defined in the various English and Non-English character sets. These datatypes take twice as much storage space per characters as non-Unicode data types.
It is not the disk space costs that are the concern. It is the 8060 limit, please refer to Maximum Capacity Specifications for SQL Server for details.
If your database stores only English characters, this is a waste of space. Don't use Unicode double-byte datatypes such as nchar and nvarchar unless you are doing multilingual applications.
If you need to store more that 255 Characters, use Varchar(max) or nvarchar(max).
Use
VARCHARinstead ofCHAR, unless your data is almost always of a fixed length, or is very short. For example, a Social Security/Tax File number which is always 9 characters. These situations are rare.SQL Server fits a whole row on a single page, and will never try to save space by splitting a row across two pages.
Running
DBCC SHOWCONTIGagainst tables shows that a table with fixed length columns takes up less pages of storage space to store rows of data.General rule is that the shorter the row length, the more rows you will fit on a page, and the smaller a table will be.
It allows you to save disk space and it means that any retrieval operation such as
SELECT COUNT(*) FROM, runs much quicker against the smaller table.Follow the below standards for tables and columns.
- All tables should have the following fields:
Field SQL Server Field Properties CreatedUtc datetime2 Allow Nulls=False Default=GETUTCDATE() CreatedUserId Foreign Key to Users table, Allow Nulls=False ModifiedUtc datetime2 Allow Nulls=False Default=GETUTCDATE() ModifiedUserId Foreign Key to Users table, Allow Nulls=False Concurrency rowversion Allow Nulls=False 
Figure: The first three are examples of bad table records. The last one is an example of how this table structure should be entered Note #1: Never set the CreatedUtc field - instead use a default GETUTCDATE()
Note #2: These fields offer basic row auditing that will cover the majority of applications. When an application has specific auditing requirements, they should be analysed to see if this approach is sufficient.
- All databases should have a table with one record to store application Defaults. This table should be called 'Control'.
If the settings are not application-wide, but just for that user then an XML (do not use an INI file) for simple stuff might be better. Examples are saving the 'User' for logon, 'Select Date Range' for a report, form positions, etc.
.NET programs have an Application.Configuration which exports to XML file (app.config) automatically. It works very well, and deployment is very simple. It's integrated right into the Visual Studio.NET designer as well.
- All databases should have a version table to record structural changes to tables. See SSW Rules to Better Code
- Lookup tables that have just two columns should be consistent and follow this convention: CategoryId (int) and CategoryName (varchar(100)).
The benefit is that a generic lookup form can be used. You will just need the generic lookup form pass in the TableName and Column1 and Column2.
Note #3: The problem with the naming is the primary keys don't match.
Note #4: The benefit with the character primary key columns is that queries and query strings have meaning Eg. ssw.com.au/ssw/Download/Download.aspx?GroupCategoryID=5BUS from this URL I can guess that it is in the business category.
1. Bit data type
Bit data from 0 to 1 (2 values only). Storage size is 1 byte.
Columns of type bit cannot have indexes on them.
Columns of type bit should be prefixed with "Is" or a "Should" ie.
IsInvoiceSent (y/n)orShouldInvoiceBeSent (y/n)you can tell easily which way the boolean is directed. See more information on naming conventions.This being said, fields of this type should generally be avoided because often a field like this can contain a date i.e.
DateInvoiceSent (Date/Time)is prefered overInvoiceSent (y/n). If a date is inappropriate then we still recommend an int field over a bit field anyway, because bits are a pain!2. Tinyint data type
Integer data from 0 through 255. Storage size is 1 byte.
3. Smallint data type
Integer data from -2^15 (-32,768) through 2^15-1 (32,767). Storage size is 2 bytes.
4. Int data type
Integer (whole number) data from -2^31 (-2,147,483,648) through 2^31-1 (2,147,483,647). Storage size is 4 bytes. The SQL-92 synonym for int is integer.
5. Bigint data type
Integer (whole number) data from -2^63 (-9223372036854775808) through 2^63-1 (9223372036854775807). Storage size is 8 bytes.
Recommendations:
- Use smallint datatype instead of bit datatype - so it can be indexed;
- Use int datatype, where possible, instead of bigint datatype - for saving disk space;
- Use smallint datatype, where possible, instead of int datatype - for saving disk space;
- Use tinyint datatype, where possible, instead of smallint datatype - for saving disk space;
Now, this is a controversial one. Which one do you use?
-
A "Natural" (or "Intelligent") key is actual data
- Surname, FirstName, DateOfBirth
-
An "Acquired Surrogate" (or "Artificial" or "System Generated") key is NOT derived from data eg. Autonumber
- eg. ClientID 1234
- eg. ClientID JSKDYF
- eg. ReceiptID 1234
-
A "Derived Surrogate" (or "User Provided") key is indirectly derived from data eg. Autonumber
- eg. ClientID SSW (for SSW)
- eg. EmpID AJC (for Adam Jon Cogan)
- eg. ProdID CA (for Code Auditor)
- A "GUID" key automatically generated by SQL Server
The problems with Natural Keys:
- Because they have a business meaning, if that meaning changes (eg. they change their surname), then that value NEEDS to change. Changing a value with data is a little hard - but a lot easier with Cascade Update.
- The main problem is that the key is large and combined and this needs to be used in all joins
The Problem with Acquired Surrogate Keys:
- A surrogate key has no meaning to a user
- It always requires a join when browsing a child table eg. The InvoiceDetail table
The Problem with Derived Surrogate
- The user needs to enter a unique value
- Because they have a business meaning, if that meaning changes (eg. they change their company name), then that value MAY NEED to change. Changing a value with data is a little hard - but a lot easier with Cascade Update
- More likely to have a problem with Merge Replication
The Problem with GUID key
We like GUID keys. However, GUID generation produces essentially random numbers which cannot realistically be used as primary keys since new rows are inserted into the table at random positions leading to extremely slow inserts as the table grows to a moderate size. Inserting into the middle of a table with a clustered index, rather than appending to the end can potentially cause the database to have to move large portions of the data to accommodate space for the insert. This can be very slow.
Recommendations
- We do not use Natural keys ever
-
We use Acquired Surrogate for some tables
- eg. Invoice table
- eg. Receipt table
-
a combination of Acquired Surrogate and Derived Surrogate for other tables
- eg. Customer table
- eg. Employee table
- eg. Product table
When we say combination because if the user doesn't enter a value then we put a random value in (by a middle-tier function, so it works with Access or SQL). eg. ClientID JSKDYFThe user can then change the value to anything else and we validate it is not used, and then perform a cascade update - or if it is more then 3 levels deep we execute a stored proc. Unfortunately, this is a complicated proc that cycles through all related tables and performs an UPDATE. Here is an example.
The Derived Surrogate has the benefit of being easy for people to remember and can be used in the interface or even the query string
Over the years experience has lead me to the opinion that the natural vs surrogate key argument comes down to a style issue. If a client or employer has a standard one way or another, fine use it. If not, use whichever you method you prefer, recognizing that there may be some annoyances you face down the road. But don't let somebody criticize you because your style doesn't fit his preconceived notions.
-
When you specify a PRIMARY KEY constraint for a table, SQL Server enforces data uniqueness by creating a unique index for the primary key columns. This index also permits fast access to data when the primary key is used in queries.Although, strictly speaking, the primary key is not essential - we recommend all tables have a primary key (except tables that have a high volume of continuous transactions).
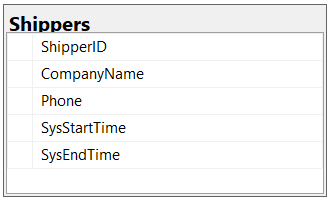
Figure: Bad Example - Table missing primarykey
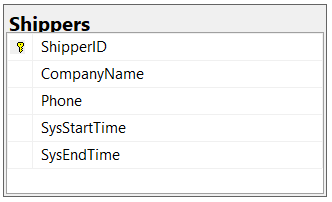
Figure: Good Example - Table with primary key
Legacy:
Especially, when you have a client like Access, it would help you to avoid the problems.
You're allowed one clustered index per table, so unless you are never going to query a table, you may as well choose a field to be part of a clustered index. Basically,
- Every table should have a clustered index;
- The clustered index should be a unique clustered index where possible;
- The clustered index should be on a single column where possible;
So how do you choose the right field? Depending on the usage pattern of a table, clustered indices should be created. If sets of related records are regularly retrieved from a table in an application, a clustered index could dramatically improve performance.For example, in an Order to OrderDetails relationship with OrderID as the joining key, items in an order are regularly retrieved in a bundle. A clustered index on the OrderID column in the OrderDetails table will improve the performance of the application significantly.Another example, if a table is frequently used for reporting, and a date range is used to define the time scope of the report, a clustered index on the date column is suitable. In more technical terms, if queries such as...
SELECT * FROM ReportTable WHERE ItemDate BETWEEN 1/1/2003 AND 1/2/2003...is executed frequently, ItemDate is a good candidate column for a clustered index.
RowGuids (uniqueidentifier) are large fields (16 bytes) and are basically going to ALWAYS be unique.
SQL Server adds a RowGUID column to all tables if you are using Merge Replication (but doesn't add an index).
RowGuids in general slow things down. Some people may consider using a RowGuid as their primary key. This is a bad idea because the index is going to be quite slow.... you are searching a large field. It goes without saying, NEVER have clustered index on a RowGuid column.
Another little annoyance with RowGuids is when you are searching for one. You can't use > or < on a RowGuid column.
**Note: ** There are not many cases where a RowGuid should have an index on it.
Be aware that SQL server adds this column when you perform merge replication. There are not many cases where this should have an index on it.
SQL Server rowversions are a data type available which are binary numbers that indicate the relative sequence in which data modifications took place in a database. See the MSDN article on rowversions here: rowversion (Transact-SQL)
All tables should have a rowversion column called "RecordVersion" to aid concurrency checking. A rowversion improves update performance because only one column needs to be checked when performing a concurrency check (instead of checking all columns in a table for changes).
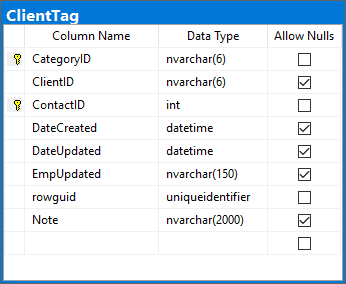
Figure: Bad Example - No rowversion available in this table
CREATE TABLE MyTest (myKey int PRIMARY KEY ,myValue int, RecordVersion rowversion); GO INSERT INTO MyTest (myKey, myValue) VALUES (1, 0); INSERT INTO MyTest (myKey, myValue) VALUES (2, 0); INSERT INTO MyTest (myKey, myValue) VALUES (3, 0); UPDATE MyTest SET myValue = 1 WHERE myKey = 2 SELECT * FROM MyTest ORDER BY RecordVersion DESCFigure: Good Example - A create statement which builds a table with a rowversion
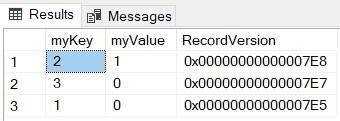
Figure: Good Example - A set of records with a rowversion available
Indexes should generally have a fillfactor of 90%. If the amount of data stored in the database does not prohibit rebuilding indexes, a fillfactor of 90% should be maintained to increase the performance of inserts.
A table that expects a lot of insert operations could use a lower fillfactor.
We always use two tables for tracking versioning information:
- _zsDataVersion tracks the schema changes, and which update script we are up to. This helps tremendously in determining which version of the scripts are still required between development, test, and production databases.
- _zsVersionLatest tracks which version the front-end client should be. This allows us to give a warning to (or even deny) users who are connecting to the database while not using the right version of the front-end client.
Please see "Is a Back-end structural change going to be a hassle?" on our Rules to Successful Projects.
When you have a denormalized field, use a computed column. In SQL Server they can be persisted.
Use the suffix "Computed" to clearly distinguish that this field is a computed field.

Figure: Bad Example - This field was manually updated from code in the middle tier. 
Figure: Good Example - There was no code in the middle tier to calculate this (and it has the correct name) Computed columns have some limitations - they cannot access fields in other tables, or other computed fields in the current table.
You can use user-defined functions (UDF) from code in a reusable function, this allows one computed column to use a function to call another function. Here is an example:
ALTER FUNCTION [dbo].[udfEmpTime_TimeTotalComputed] ( @TimeStart as DateTime, @TimeEnd as DateTime ) RETURNS DECIMAL(8,6) AS BEGIN -- This function returns the time difference in hours - decimal(8,6) RETURN (round(isnull(CONVERT([decimal](8,6),@TimeEnd - @TimeStart,(0))*(24),(0)),(2))) ENDFigure: This is the user defined function

Figure: Setting up a computed column in the table designer Ideally you should be using computed columns as per Do you use computed columns rather than denormalized fields?
You can also have a denormalized field that is manually updated. This should be the exception and not the rule. When used properly and sparingly, they can actually improve your application's performance.
As an example:
- You have an Orders table containing one record per order
- You also have an OrderItems table which contains line items linked to the main OrderID, as well as subtotals for each line item
- In your front end, you have a report showing the total for each order
To generate this report, you can either:
- Calculate the Order total by summing up every single line item for the selected Order every time the report is loaded, or
- Store the Order subtotal as a de-normalised field in the Orders table which gets updated using trigger.
The second option will save me an expensive JOIN query each time because you can just tack the denormalised field onto the end of my SELECT query.
1. Code: Alter Orders table
ALTER TABLE Orders ADD SumOfOrderItems money NULL- Code: Insert trigger
Alter Trigger tri_SumOfOrderItems On dbo.OrderItems For Insert AS DECLARE @OrderID varchar (5) SELECT @OrderID = OrderID from inserted UPDATE Orders SET Orders.SumOfOrderItems = Orders.SumOfOrderItems + (SELECT isnull(SUM(ItemValue),0) FROM inserted WHERE inserted.OrderID = Orders.OrderID) WHERE Orders.OrderID = @OrderID- Code: Update trigger
Alter Trigger tru_SumOfOrderItems On dbo.OrderItems For Update AS DECLARE @OrderID varchar (5) SELECT @OrderID = OrderID from deleted --Could have used inserted table UPDATE Orders SET Orders.SumOfOrderItems = Orders.SumOfOrderItems + (SELECT isnull(SUM(ItemValue),0) FROM inserted WHERE inserted.OrderID = Orders.OrderID) - (SELECT isnull(SUM(ItemValue),0) FROM deleted WHERE deleted.OrderID = Orders.OrderID) WHERE Orders.OrderID = @OrderID- Code: Delete trigger
Alter Trigger trd_SumOfOrderItems On dbo.OrderItems For Delete AS DECLARE @OrderID varchar (5) SELECT @OrderID = OrderID FROM deleted UPDATE Orders SET Orders.SumOfOrderItems = Orders.SumOfOrderItems - (SELECT isnull(SUM(ItemValue),0) FROM deleted WHERE deleted.OrderID = Orders.OrderID) WHERE Orders.OrderID = @OrderID- Code: Maintenance stored procedure
--Stored Procedure for Maintenance Alter Procedure dt_Maintenance_SumOfItemValue As UPDATE Orders SET Orders.SumOfOrderItems = Isnull((SELECT SUM (ItemValue) FROM OrderItems WHERE OrderItems.OrderID = Orders.OrderID),0)User-schema separation allows more flexibility by adding another level of naming and shifting ownership of database objects to the schema, not the user. So, is it worth doing? Unless you are working with a very large database (100+ tables), the answer is "no". Most smaller databases have all objects with owner "dbo", which is fine in most cases.
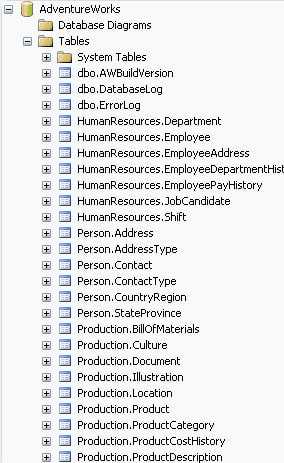
Figure: Bad Example - AdventureWorks using user schema - instead, keep it simple and avoid using user schema unnecessarily 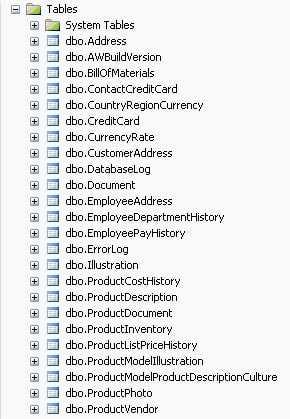
Figure: Good Example - Adventure works with user schema cleaned out. Much simpler and more readable Make sure you created a consistent primary key column named Id on your tables.
Employee.ID, Employee.EmployeeId, Employee.EmployeeID, Employee.Employee_Code, Employee.EmployeeFigure: Bad example
Employee.IdFigure: Good example
Why?
- We shouldn’t capitalise ID (identifier) as it is an abbreviation not an acronym.
- Using the approach [TableName]Id, e.g. EmployeeId, is redundant as we already know the context of the Id.
Advantage: Simplifies ORM Mapping
We prefer multiple lookup tables so they make more sense in ORM tools. If you have multiple lookups to the one table, you would need to do your mappings manually rather than using a tool. E.g. you could have either: LookupTable or OrderType
When you are obtaining the OrderType for an order, you would have either:
- Order.OrderType.OrderTypeID
Good as it is clear what is being retrieved from the lookup table.
- Order.LookupTable.Value
Not great as it is not clear what the nature of the lookup table is.
Advantage: Maintains Complete Referential Integrity without the need for triggers
The other advantage of having separate lookup tables rather than one large one is that referential integrity is maintained.One issue with having one large table is that you can still enter invalid values in the Order.OrderTypeID column. E.g. if Order TypeIDs range from 1-3 and CustomerTypeIDs range from 4 to 10.
If I put OrderTypeID = 10, then I will not get referential integrity errors (even though I should) because I have entered a value which exists in the lookup table (even though it is for the wrong type).
If I want to enforce referential integrity so I can only enter the correct type for my lookup table, then I would need to resort to triggers or a (fallible) coded data tier.
Advantage: You can add new columns specific to each lookup table
For example, if a Lookup table (e.g. CustomerType) has an associated value (e.g. the field MaximumDebtAmount), we don't need to add a field that is irrelevant to all the other lookup tables. We can just add it to the individual lookup table.
Disadvantage: Multiple tables make maintenance slightly more difficult, especially when making changes directly via Management Studio
It is simpler to Administer one table than multiple tables, but you can reduce this problem with a good Generic Administration Page UI.
You should not provide a database schema via several screen captures - it has little information about the details. A well-formatted Word document may be providing more details information, but it is not easy to maintain the document to keep it up-to-date. The best way is to automatically generate your document with a tool.
We recommend and use Red-Gate SQL Doc to produce chm help files or html pages of the database schema. SQL Doc also allows you to run via the command line so you can include the generation in your build process to be automatically created.
We have also have used other available tools in the past, such as Apex SQL Doc.
Alternatively, you can use SQL Management Studio to generate a Database diagram.
- Connect to your database using SQL Server Management Studio
- Create a new Database Diagram, by right-clicking Database Diagrams
**
 Figure: New Database Diagram
**
Figure: New Database Diagram
** - A popup will appear. Shift-Click to select all the tables then click Add
 **Figure: Selecting tables for diagram
**
**Figure: Selecting tables for diagram
** - You will see tables populate behind the dialogue box, once complete click Close
 **Figure: Tables populated
**
**Figure: Tables populated
** - Click off the tables in the diagram and Ctrl+A to Select all
- Right-Click one of the tables in the diagram and perform the following
a. Select Table View | Standard from the menu
b. Select Autosize Selected Tables from the menu
 **Figure: Changing the database table diagram to Standard View and Autosize
**
**Figure: Changing the database table diagram to Standard View and Autosize
**- Right-click the diagram background and select Show Relationship Labels
 **Figure: Show Relationship Labels
**
**Figure: Show Relationship Labels
** - Move the tables around so that the Relationship Labels are clearly visible.
Note: You will need to screenshot the diagram as using the copy to clipboard function removes the “Allow Nulls” checkmarks.
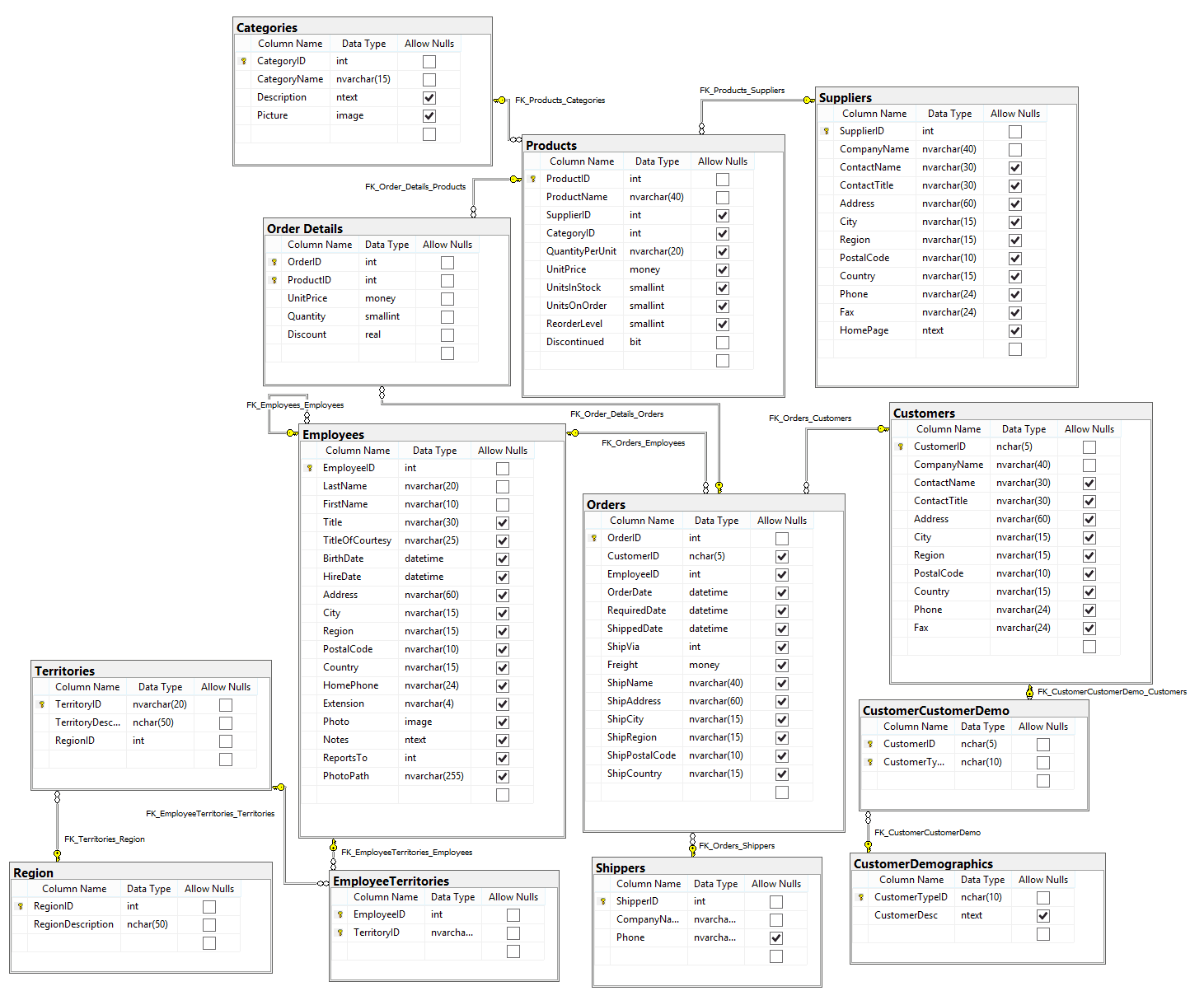
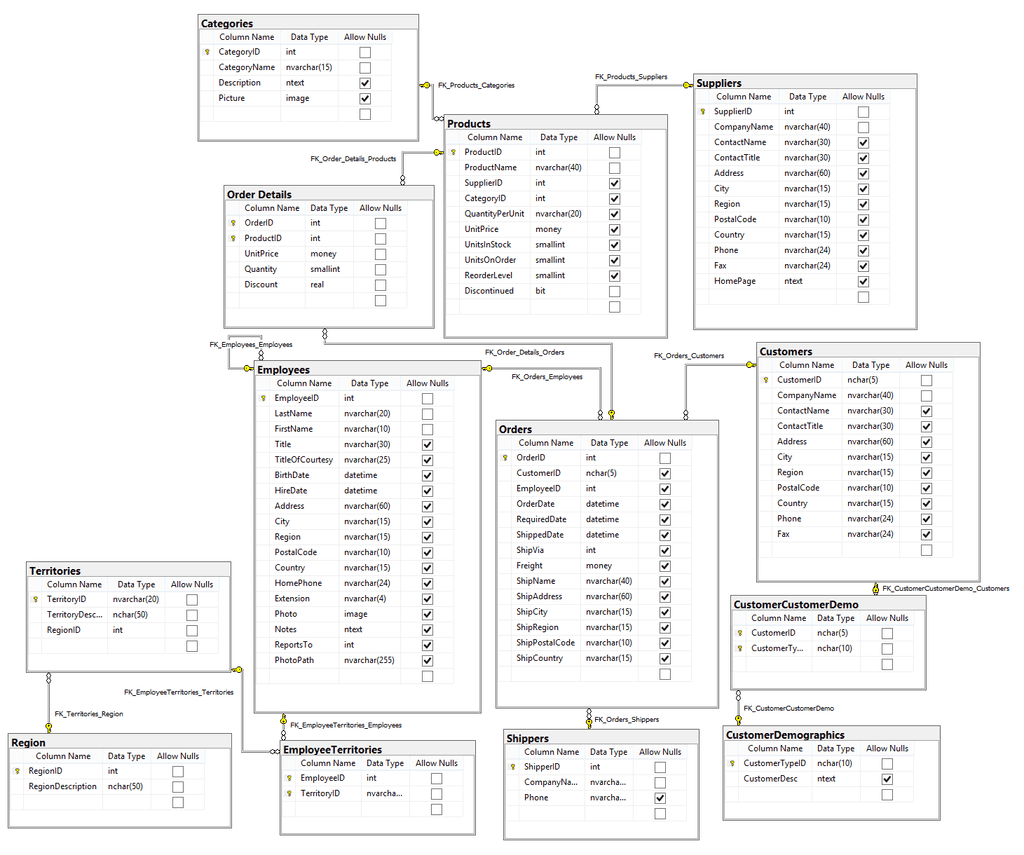 **Figure: Northwind Database Schema
**
**Figure: Northwind Database Schema
**Any type of table in a database where that does not contain application data should be called zs. So when the other application (e.g. SSW SQL Deploy) or the programmer populates the table then it should be called zs (e.g. zsDate - the program populates it, zsVersion - the programmer populates it).
Don't have views as redundant objects. e.g. vwCustomers as SELECT * FROM Customers. This is unnecessary. Instead, Views should be generally used for security.
The reason is that you avoid ownership chain problems. Where Mary owns an object, Fred can read the object and then he creates a proc and he gives permission to Tom to execute. But Tom cannot because there is a product chain of ownership.
CREATE PROCEDURE [Adam Cogan].[Sales by Year] @Beginning_Date DateTime, @Ending_Date DateTime AS SELECT Orders.ShippedDate ,Orders.OrderID ,"vwOrderSubTotals".Subtotal ,DATENAME(yy,ShippedDate) AS Year FROM Orders INNER JOIN "vwOrderSubTotals" ON Orders.OrderID = "vwOrderSubTotals".OrderID WHERE Orders.ShippedDate Between @Beginning_Date And @Ending_DateFigure: Bad Example
CREATE PROCEDURE [dbo].[Sales by Year] @Beginning_Date DateTime, @Ending_Date DateTime AS SELECT Orders.ShippedDate ,Orders.OrderID ,"vwOrderSubTotals".Subtotal ,DATENAME(yy,ShippedDate) AS Year FROM Orders INNER JOIN "vwOrderSubTotals" ON Orders.OrderID = "vwOrderSubTotals".OrderID WHERE Orders.ShippedDate Between @Beginning_Date And @Ending_DateFigure: Good Example
If you are using the .NET Framework, put validation and defaults in the middle tier. The backend should have the required fields (Allow Nulls = False), but no complicated constraints. The following are examples that work with the Products table (with an added timestamp field called Concurrency) from Northwind.
1. Code: Select Procedure
ALTER PROCEDURE dbo.ProductSelect @ProductID int AS SELECT ProductName, SupplierID, CategoryID, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued, Concurrency FROM Products WHERE (ProductID= @ProductID)2. Code: Insert Procedure
ALTER PROCEDURE dbo.ProductInsert @ProductName nvarchar(40), @SupplierID int, @CategoryID int, @QuantityPerUnit nvarchar(20), @UnitPrice money, @UnitsInStock smallint, @UnitsOnOrder smallint, @ReorderLevel smallint, @Discontinued bit AS INSERT INTO Products (ProductName, SupplierID, CategoryID, QuantityPerUnit, UnitPrice, UnitsInStock, UnitsOnOrder, ReorderLevel, Discontinued) VALUES (@ProductName, @SupplierID, @CategoryID, @QuantityPerUnit, @UnitPrice, @UnitsInStock, @UnitsOnOrder, @ReorderLevel, @Discontinued, 1) SELECT Scope_Identity() AS [SCOPE_IDENTITY] --If table has identity column --SELECT @@ROWCOUNT --If table doesn't have identity column -- Note: The middle tier must check the ROWCOUNT = 13.Code: Update Procedure
ALTER PROCEDURE dbo.ProductUpdate @ProductID int, @ProductName nvarchar(40), @SupplierID int, @CategoryID int, @QuantityPerUnit nvarchar(20), @UnitPrice money, @UnitsInStock smallint, @UnitsOnOrder smallint, @ReorderLevel smallint, @Discontinued bit, @Concurrency timestamp UPDATE Products SET ProductName = @ProductName, SupplierID = @SupplierID, CategoryID = @CategoryID, QuantityPerUnit = @QuantityPerUnit, UnitPrice = @UnitPrice, UnitsInStock = @UnitsInStock, UnitsOnOrder = @UnitsOnOrder, ReorderLevel = @ReorderLevel, Discontinued = @Discontinued WHERE (Concurrency = @Concurrency) AND (ProductID= @ProductID) --Note the double criteria to ensure concurrency SELECT @@ROWCOUNT -- Note: The middle tier must check the ROWCOUNT = 14.Code: Delete Procedure
ALTER PROCEDURE dbo.ProductDelete @ProductID int, @Concurrency timestamp AS DELETE FROM Products WHERE (ProductID= @ProductID) AND (Concurrency = @Concurrency) --Note the double criteria to ensure concurrency SELECT @@ROWCOUNT --Note: The middle tier must check the ROWCOUNT = 1Make sure your stored procedures always return a value indicating the status. All stored procedures should return the error number (if an error) or a 0 to indicate no errors (ie success).
Standardize on the return values of stored procedures for success and failures.
The RETURN statement is meant for returning the execution status only, but not data. If you need to return the value of variables, use OUTPUT parameters. There is a compelling reason for this - if you use return values rather than output values to return data, money values that you return will silently be truncated.
Always check the global variable @@ERROR immediately after executing a data manipulation statement (like INSERT/UPDATE/DELETE), so that you can rollback the transaction in case of an error (@@ERROR will be greater than 0 in case of an error). This is important, because, by default, SQL Server will not rollback all the previous changes within a transaction if a particular statement fails. This behaviour can be changed by executing SET XACT_ABORT ON. The @@ROWCOUNT variable also plays an important role in determining how many rows were affected by a previous data manipulation (also, retrieval) statement, and based on that you could choose to commit or rollback a particular transaction.
When inserting a row in a stored procedure, always use SCOPE_IDENTITY() if you want to get the ID of the row that was just inserted. A common error is to use @@IDENTITY, which returns the most recently created identity for your current connection, not necessarily the identity for the recently added row in a table. You could have a situation where there is a trigger that inserts a new record in a Logs Table, for example, when your Stored Procedure or INSERT SQL Statement inserts a record in the Orders Table. If you use @@IDENTITY to retrieve the identity of the new order, you will actually get the identity of the record added into the Log Table and not the Orders Table, which will create a nasty bug in your data access layer. To avoid the potential problems associated with someone adding a trigger later on, always use SCOPE_IDENTITY() to return the identity of the recently added row in your INSERT SQL Statement or Stored Procedure.
Behold this example from SQL Server Books online.
USE tempdb GO CREATE TABLE TZ ( Z_id int IDENTITY(1,1)PRIMARY KEY, Z_name varchar(20) NOT NULL) INSERT TZ VALUES ('Lisa') INSERT TZ VALUES ('Mike') INSERT TZ VALUES ('Carla') SELECT * FROM TZ --Result set: This is how table TZ looks. Z_id Z_name ------------- 1 Lisa 2 Mike 3 Carla CREATE TABLE TY ( Y_id int IDENTITY(100,5)PRIMARY KEY, Y_name varchar(20) NULL) INSERT TY (Y_name) VALUES ('boathouse') INSERT TY (Y_name) VALUES ('rocks') INSERT TY (Y_name) VALUES ('elevator') SELECT * FROM TY --Result set: This is how TY looks: Y_id Y_name --------------- 100 boathouse 105 rocks 110 elevator /*Create the trigger that inserts a row in table TY when a row is inserted in table TZ*/ CREATE TRIGGER Ztrig ON TZ FOR INSERT AS BEGIN INSERT TY VALUES ('') END /*FIRE the trigger and determine what identity values you obtain with the @@IDENTITY and SCOPE_IDENTITY functions.*/ INSERT TZ VALUES ('Rosalie') SELECT SCOPE_IDENTITY() AS [SCOPE_IDENTITY] GO SELECT @@IDENTITY AS [@@IDENTITY] GONotice the difference in the result sets. As you can see, it's crucial that you understand the difference between the 2 commands in order to get the correct ID of the row you just inserted.
SCOPE_IDENTITY 4 /*SCOPE_IDENTITY returned the last identity value in the same scope. This was the insert on table TZ.*/ @@IDENTITY 115 /*@@IDENTITY returned the last identity value inserted to TY by the trigger. This fired because of an earlier insert on TZ.*/You should use SET NOCOUNT ON for production and NOCOUNT OFF off for development/debugging purposes (i.e. when you want the rowcounts to display as the messages from your T-SQL).
According to SQL Server Books Online:"For stored procedures that contain several statements that do not return much actual data, this can provide a significant performance boost because network traffic is greatly reduced."
Example: Procedure that returns a scalar value (ClientID generated by an insert statement) should use OUTPUT keyword (not RETURN) to pass back data. This is how you should return a generated ClientID from the procedure, and also return a status value
CREATE PROCEDURE procClientInsert /* '---------------------------------------------- ' Copyright 2001 SSW ' www.ssw.com.au All Rights Reserved. ' VERSION AUTHOR DATE COMMENT ' 1.0 DDK 17/12/2001 ' 'Calling example 'DECLARE @pintClientID int 'DECLARE @intReturnValue int 'exec @intReturnValue = procClientInsert 'TEST Entry', @pintClientID OUTPUT 'PRINT @pintClientID 'PRINT @intReturnValue '---------------------------------------------- */ @pstrCoName varchar (254), @pintClientID int OUTPUT AS --IF ONE THING FAILS, ROLLBACK SET XACT_ABORT ON --THE COUNT WILL NOT NORMALLY DISPLAY IN AN APPLICATION IN PRODUCTION. --GET RID OF IT BECAUSE IT IS EXTRA TRAFFIC, AND CAN CAUSE PROBLEMS WITH SOME CLIENTS SET NOCOUNT ON --Generate a random number SET @pintClientID = (SELECT CAST(RAND() * 100000000 AS int)) INSERT INTO Client (ClientID, CoName) VALUES (@pintClientID , @pstrCoName) SET XACT_ABORT OFF IF @@ROWCOUNT = 1 RETURN 0 -- SUCCESS ELSE BEGIN IF @@ERROR=0 RETURN 1 -- FAILURE ELSE RETURN @@ERROR -- FAILURE END SET NOCOUNT OFFThis procedure will display 0 or the error to indicate success or failure. You should base your actions on this return code.
This separates return values from actual data so that other programmers know what to expect.
Note: If you are using SQL Server stored procedures to edit or delete data using a SqlDataAdapter, make sure that you do not use SET NOCOUNT ON in the stored procedure definition. This causes the rows affected count returned to be zero, which the DataAdapter interprets as a concurrency conflict. In this event, a DBConcurrencyException will be thrown.
System stored procedures are created and stored in the master database and have the sp_ prefix. System stored procedures can be executed from any database without having to qualify the stored procedure name fully using the database name master. It is strongly recommended that you do not create any stored procedures using sp_ as a prefix. SQL Server always looks for a stored procedure beginning with sp_ in this order:
- The stored procedure in the master database.
- The stored procedure based on any qualifiers provided (database name or owner).
- The stored procedure using dbo as the owner, if one is not specified.
Therefore, although the user-created stored procedure prefixed with sp_ may exist in the current database, the master database is always checked first, even if the stored procedure is qualified with the database name.
Important: If any user-created stored procedure has the same name as a system stored procedure, the user-created stored procedure will never be executed.
Using a statement like "INSERT tableName SELECT * FROM otherTable", makes your stored procedures vulnerable to failure. Once either of the two tables change, your stored procedure won't work. Not only that, when the inserting table has an identity column, such a statement will cause an error - "An explicit value for the identity column in table ParaRight can only be specified when a column list is used and IDENTITY_INSERT is ON."
USE [ParaGreg] GO /****** Object: StoredProcedure [dbo].[procMove] Script Date: 08/08/2008 12:18:33 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER PROCEDURE [dbo].[procMove] @id AS Char, @direction AS INT AS IF @direction = 0 BEGIN INSERT INTO ParaRight SELECT * FROM ParaLeft WHERE ParaID = @id DELETE FROM ParaLeft WHERE ParaID = @id END ELSE IF @direction = 1 BEGIN INSERT INTO ParaLeft SELECT * FROM ParaRight WHERE ParaID = @id DELETE FROM ParaRight WHERE ParaID = @id ENDFigure: Bad Example - Using SELECT * when inserting data. Besides, this stored procedure should have an Else section to raise error when no condition is satisfied
USE [ParaGreg] GO /****** Object: StoredProcedure [dbo].[procMove] Script Date: 08/08/2008 12:18:33 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER PROCEDURE [dbo].[procMove] @id AS Char, @direction AS INT AS IF @direction = 0 BEGIN INSERT INTO ParaRight SELECT Col1,Col2 FROM ParaLeft WHERE ParaID = @id DELETE FROM ParaLeft WHERE ParaID = @id END ELSE IF @direction = 1 BEGIN INSERT INTO ParaLeft SELECT * FROM ParaRight WHERE ParaID = @id DELETE FROM ParaRight WHERE ParaID = @id END ELSE BEGIN PRINT "Please use a correct direction" ENDFigure: Good Example - Using concrete columns instead of * and provide an Else section to raise errors
A transaction means an atomic operation, it assures that all operations within the transaction are successful, if not, the transaction will cancel all operations and roll back to the original state of the database, that means no dirty data and mess exists in the database, so if a stored procedure has many steps, and each step has relation with other steps, it is strongly recommended that you encapsulate the procedure in a transaction.
ALTER PROCEDURE [dbo].[procInit] AS DELETE ParaLeft DELETE ParaRight INSERT INTO ParaLeft (ParaID) SELECT ParaID FROM ParaFigure: Bad Example - No transaction here, if any of operations fail, the database will only partially update, resulting in an unwanted result.
ALTER PROCEDURE [dbo].[procInit] AS BEGIN TRANSACTION DELETE ParaLeft DELETE ParaRight INSERT INTO ParaLeft (ParaID) SELECT ParaID FROM Para COMMITFigure: Good Example - Using a transaction to assure that all operations within the transaction will be successful, otherwise, the database will roll back to the original state.
You should always include error handling in your stored procedures, it allows you to catch errors and either log them or attempt to correct them.THROW (Transact-SQL) lets you generate your own custom error messages, which can be more detailed in describing the problem and assist in debugging.
Here’s an example of the syntax used when implementing THROW.
-- Syntax THROW error_number, message, state;Figure: Example of the THROW syntax
There are 3 main arguments:
- error_number (int) - Must be greater than or equal to 50000 and less than or equal to 2147483647.
- message (nvarchar) - Maximum of 2048 characters.
- state (tinyint) - Must be between 0 and 255
The state argument can be used to help pinpoint where the error occurred by using a different value without changing the error_number or message . This is useful if you have multiple steps in a process that may throw identical error descriptions.
-- Example THROW 51000, 'The record does not exist.', 1;Figure: Example of using THROW
Implementing Error Handling using THROW
Here we are generating a divide-by-zero error to easily raise a SQL exception and is used as a place holder for logic that we would have in our stored procedure.
DECLARE @inputNumber AS INT = 0; -- Generate a divide-by-zero error SELECT 1 / @inputNumber AS Error;Figure: Bad Example - No error handling.
Below we have wrapped our stored procedure logic in a TRY block and added a CATCH block to handle the error. More information can be found here TRY...CATCH (Transact-SQL).
We know this divide-by-zero is going to cause an exception and the error number for this specific SQL exception is 8134. See (MSSQL Errors) for more error numbers.
In our CATCH block, we check the error to ensure it’s the one that we want to handle otherwise, we re-throw the original exception.Finally, when we catch the error we are looking for we can log some information about it and attempt to run our stored procedure logic again with different parameters.
DECLARE @errorCode AS INT; DECLARE @inputNumber AS INT; BEGIN TRY -- Generate a divide-by-zero error SET @inputNumber = 0; SELECT 1 / @inputNumber AS Error; END TRY BEGIN CATCH SET @errorCode = (SELECT ERROR_NUMBER()); IF @errorCode = 8134 -- Divide by zero error encountered. BEGIN PRINT 'Divide by zero error encountered. Attempting to correct' SET @inputNumber = 1; SELECT 1 / @inputNumber AS Error; END ELSE THROW; END CATCH;Figure: Good Example - Using error handling to catch an error and attempt to resolve it.
The example below shows how you can catch an error and retrieve all the details about it.This is very useful if you want to save these errors to another table or trigger a stored procedure.
BEGIN TRY -- Generate a divide-by-zero error. SELECT 1 / 0 AS Error; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_STATE() AS ErrorState, ERROR_SEVERITY() AS ErrorSeverity, ERROR_PROCEDURE() AS ErrorProcedure, ERROR_LINE() AS ErrorLine, ERROR_MESSAGE() AS ErrorMessage; -- Insert logic for persisting log information (Log to table or log to file) THROW; END CATCH;Figure: Good Example - Using error handling to catch an error and retrieving its details, allowing it to be logged.
Always specify the schema prefix when creating stored procedures. This way you know that it will always be dbo.procedure_name no matter who is logged in when it is created.
There are 2 other benefits to including the schema prefix on all object references:
- This prevents the database engine from checking for an object under the users schema first
- Also avoids the issue where multiple plans are cached for the exact same statement/batch just because they were executed by users with different default schemas.
Aaron Bertrand agrees with this rule - My stored procedure "best practices" checklist.
CREATE PROCEDURE procCustomer_Update @CustomerID INT, ….. BEGINFigure: Bad example
CREATE PROCEDURE dbo.procCustomer_Update @CustomerID INT, ….. BEGINFigure: Good example
Cascading referential integrity constraints allow you to define the actions SQL Server takes when a user attempts to delete or update a key to which existing foreign keys point. The REFERENCES clauses of the CREATE TABLE and ALTER TABLE statements support ON DELETE and ON UPDATE clauses:
- [ ON DELETE { CASCADE | NO ACTION } ]
- [ ON UPDATE { CASCADE | NO ACTION } ]
NO ACTION is the default if ON DELETE or ON UPDATE is not specified.
Relationships should always have referential integrity turned on. If you turned it on after data has been added, you may have data in your database that violates your referential integrity rules.
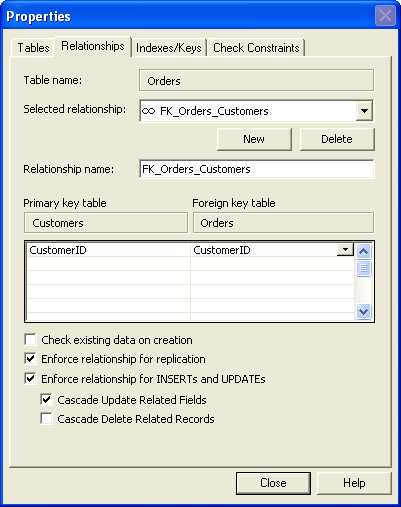
Figure: Recommended referential integrity constraints The ON UPDATE CASCADE feature of SQL Server 2000 and above can save you time in writing application and stored procedure code. We recommend that you take advantage of it. It is also more efficient than using triggers to perform these updates.moved
SQL Servers ON DELETE CASCADE functionality can be very dangerous. We recommend not using it. Imagine someone deletes customer and the orders are deleted. If you need to delete records in related tables, do it in code in the application as it gives you more control.
When NOT FOR REPLICATION is used with a Foreign Key relationship, the integrity of the relationship is not checked while the Replication Agent is logged in and performing replication operations. This allows changes to the data (such as cascading updates) be propagated correctly.
Columns ending with 'ID' should have FOREIGN KEY constraints.
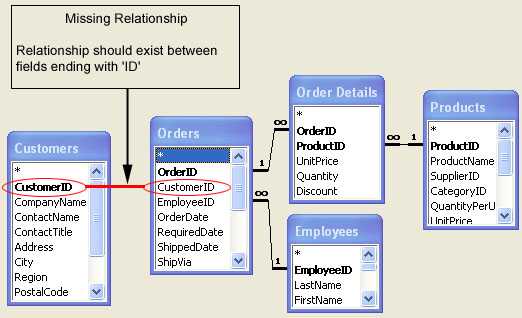
Figure: Missing relationships SQL Server reserves certain keywords for its exclusive use.
- It is not legal to include the reserved keywords in a Transact-SQL statement in any location except that defined by SQL Server.
- No objects in the database should be given a name that matches a reserved keyword.
- If such a name exists, the object must always be referred to using delimited identifiers.
- Although this method does allow for objects whose names are reserved words, it is recommended that you do not name any database objects with a name that is the same as a reserved word.
- In addition, the SQL-92 standard implemented by Microsoft SQL Server defines a list of reserved keywords.
Avoid using SQL-92 reserved keywords for object names and identifiers, ie. User, Count, Group, etc. They can be used if joined with other words.
Spaces should be avoided. If an object name contains a space, it can cause problems later on for developers because the developer must remember to put the object name inside square brackets when referencing it.
Read this article: Worst Practice - Spaces in Object Names.
We aim to never have to use square brackets in any of our databases.
Do not use "sp_rename" to rename objects like stored procedures, views and triggers.Object name should be the same as the name used in the object's script (e.g. CREATE script for stored procedures, views and triggers). Inconsistency can happen when object is renamed with sp_rename, but its script is not updated.
Follow naming conventions:
- SQL Server Object Naming Standard
- SQL Server Stored Procedure Naming Standard
- SQL Server Indexes Naming Standard
- SQL Server Relationship Naming Standard
- Use decreasing generality for table names ie.
ClientandClientInvoice, thenClientInvoiceDetail. - Don't use underscores, instead use upper and lower case ie.
ClientInvoiceis preferred overClient_Invoice. - Table names should use plural ie.
Clientsis preferred overClient. -
Generally, do not use abbreviations. But there are a few words that are so commonly used that they can be abbreviated. These are:
- Quantity =
Qty - Amount =
Amt - Password =
Pwd
- Quantity =
- Prefix all date fields with 'Date' ie.
DateInvoiced. One extra use of this is you can have generic code that enables a date control on this field. - Suffix Percent fields with 'Pct' ie.
SalesTaxPct. - Only use alphabet characters. ie. don't use
AustraliaListA$. Avoid the following characters in your object names in SQL Server. If you do not do this, you will need to constantly identify those ill-named objects with bracketed or quoted identifiers - otherwise, unintended bugs can arise. - Don't use reserved words on their own. ie.
User,Count,Group, etc. They can be used if joined with other words. See Reserved Keywords (Transact-SQL)
This standard outlines the standard on naming objects within SQL Server. Use these standards when naming any object or fix if you find an older object that doesn't follow these standards.
Object Prefix Example Table Clients Column (PK) Id Column (FK) ClientId Temporary Table _zt _ztClients System Table _zs _zsDataVersion, _zsVersionLatest View vw, gy_ vwClientsWithNoPhoneW, gy_ClientsWithNoPhoneW Stored Procedure proc, gp_ procSelectClientsClientID, gp_SelectClientsClientID Trigger trg trgOrderIU Default* dft * dftToday * Rule rul rulCheckZIP User-Defined Datatype udt udtPhone User-Defined Functions udf udfDueDates Note: We never use defaults as objects, this is really an old thing that is just there for backwards compatibility. Much better to use a default constraint.
Other Links
- SQL Server Coding Standards - Part 1 by Steve Jones on SQL Server Central
This standard outlines the standard on naming Stored Procedures within SQL Server. Use these standards when creating new Stored Procedures or if you find an older Stored Procedure that doesn't follow these standards within SSW.
Note: Stored Procedures will run fractionally slower if they start with a prefix of sp_ This is because SQL Server will look for a system stored proc first. Therefore we never recommend starting stored procs with a prefix of sp_ Do you agree with them all? Are we missing some? Let us know what you think.
Syntax
Stored Procedure names are to have this syntax:[proc] [MainTableName] By [FieldName(optional)] [Action][ 1 ] [ 2 ] [ 3 ] [ 4 ][1] All stored procedures must have the prefix of 'proc'. All internal SQL Server stored procedures are prefixed with "sp_", and it is recommended not to prefix stored procedures with this as it is a little slower.[2] The name of the table that the Stored Procedure accesses.[3] (optional) The name of the field that are in the WHERE clause. ie. procClientByCoNameSelect, procClientByClientIDSelect[4] Lastly the action which this Stored Procedure performs.
If Stored Procedure returns a recordset then suffix is 'Select'.If Stored Procedure inserts data then suffix is 'Insert'.If Stored Procedure updates data then suffix is 'Update'.If Stored Procedure Inserts and updates then suffix is 'Save'.If Stored Procedure deletes data then suffix is 'Delete'.If Stored Procedure refreshes data (ie. drop and create) a table then suffix is 'Create'.If Stored Procedure returns an output parameter and nothing else then make the suffix is 'Output'.
ALTER PROCEDURE procClientRateOutput @pstrClientID VARCHAR(6) = 'CABLE', @pstrCategoryID VARCHAR(6) = '<All>', @pstrEmpID VARCHAR(6)='AC', @pdteDate datetime = '1996/1/1', @curRate MONEY OUTPUT AS -- Description: Get the $Rate for this client and this employee -- and this category from Table ClientRate SET @curRate = ( SELECT TOP 1 Rate FROM ClientRate WHERE ClientID=@pstrClientID AND EmpID=@pstrEmpID AND CategoryID=@pstrCategoryID AND DateEnd > @pdteDate ORDER BY DateEnd ) IF @curRate IS NULL SET @curRate = ( SELECT TOP 1 Rate FROM ClientRate WHERE ClientID=@pstrClientID AND EmpID=@pstrEmpID AND CategoryID='<ALL>' AND DateEnd > @pdteDate ORDER BY DateEnd ) RETURNFigure: Good Example - stored proc that returns only an output parameter
Select 'procGetRate' or 'sp_GetRate' Insert 'procEmailMergeAdd'
Figure: Bad Example
'procClientRateSelect' 'procEmailMergeInsert'
Figure: Good Example
This standard outlines the procedure on naming Indexes at SSW for SQL Server. Use this standard when creating new Indexes or if you find an older Index that doesn't follow that standard.
Note: There is not a lot of use naming Indexes - we only do it when we are printing out documentation or using the 'Index Tuning Wizard' - then it becomes really handy.
Index names are to have this syntax:
[pkc_] [TableName] by [FieldName]
[1] [2] [3][1] All indexes must have a corresponding prefix.
Prefix Type pkc_ Primary Key, Clustered pknc_ Primary Key, Non Clustered ncu_ Non Clustered, Unique cu_ Clustered, Unique nc_ Non Clustered (Most Common) Make unique index name if possible. Ie. ProductName
[2] The name of the table that the Index refers to.[3] The name of the column(s) that the Index refers to.
Index 'BillingID' Primary Key 'aaaaaClient\_PK'Figure: Bad Example
'nc\_ClientDiary\_BillingID' 'pknc\_ClientDiary\_ClientID'Figure: Good Example
This standard outlines the procedure on naming Relationships at SSW for SQL Server. Use this standard when creating new Relationships or if you find an older Relationship that doesn't follow that standard.
Do you agree with them all? Are we missing some? Let us know what you think.
Syntax
Relationship names are to have this syntax:
[PrimaryTable] - [ForeignTable]
[ 1 ] - [ 2 ][1] The table whose columns are referenced by other tables in a one-to-one or one-to-many relationship.Rather than accepting the default value i.e. ClientAccount_FK01 that is given from upsizing.
Figure: Bad Example - using the default relationship name We recommend using Prod-ClientAccount.
Figure: Good Example - using a more descriptive relationship name The good thing is when you look at the relationship from the other side it is there as well.
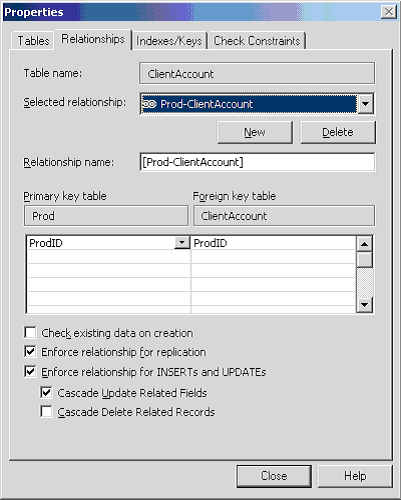
Figure: Relationship name shown on the other table We also believe in using Cascade Updates - but never cascade deletes.
Generally, every client should have a dev and a test database, so the dev database needs to have the postfix "Dev" and the test database need to have the postfix "Test"(E.g. SSWCRMDev, SSWCRMTest). However, you don't need any postfix for the production database.

Figure: Bad Example - Database with bad names 
Figure: Good Example - Database with standard names Business logic/rules should be implemented in an object oriented language such as VB.NET and C#. This dramatically increases the adaptability, extensibility and maintainability of the application.
Implementing business logic in stored procedures have the disadvantage of being hard to test, debug and evolve, therefore, they should only implement basic data access logic.
With the exception of some very heavy data oriented operations, it is excusable to use stored procedures to carry out some logic for performance reasons.
Triggers are even more difficult as their behaviour is event based. It is OK to use triggers for non-functional/infrastructural features such as logging changes or maintain more complex relational integrity which cannot be enforced by a simple relationship.
It is important to parameterize all input to your database and it’s easy to implement.Doing so will also reduce a lot of headaches down the track.
 **Figure: What can happen if you don’t parameterize your inputs
Source: xkcd.com
**
**Figure: What can happen if you don’t parameterize your inputs
Source: xkcd.com
** Advantages
- Prevents SQL injection attacks
- Preserves types being sent to the database
- Increased performance by reducing the number of query plans
- Makes your code more readable
SELECT Id, CompanyName, ContactName, ContactTitle FROM dbo.Customers WHERE CompanyName = 'NorthWind';Figure: Bad Example - Using a dynamic SQL query
SELECT Id, CompanyName, ContactName, ContactTitle FROM dbo.Customers WHERE CompanyName = @companyName;Figure: Good Example - Using a parameterized query
Should I use Parameters.AddWithValue()?
Using Parameters.AddWithValue() can be a bit of a shortcut as you don’t need to specify a type. However shortcuts often have their dangers and this one certainly does.For most cases Parameters.AddWithValue() will guess correctly, but sometimes it doesn’t which can lead to the value being misinterpreted when sent to the database. This can be avoided using Parameters.Add() and specifying the SqlDbType, this will ensure the data will reach the database in the correct form. When using dates, strings, varchar and nvarchar it is strongly recommended to use Parameters.Add() as there is a possibility of Parameters.AddWithValue() to incorrectly guess the type. Implementing parameterized queries using Parameters.Add()
cmd.Parameters.Add("@varcharValue", System.Data.SqlDbType.Varchar, 20).Value = “Text”;Figure: Good Example – Using VarChar SqlDbType and specifying a max of 20 characters (-1 for MAX)
cmd.Parameters.Add("@decimalValue", System.Data.SqlDbType.Decimal, 11, 4).Value = decimalValue;Figure: Good Example – Using decimal(11,4) SQL Parameter
cmd.Parameters.Add("@dateTimeValue", System.Data.SqlDbType.DateTime2).Value = DateTime.UtcNow;Figure: Good Example - C#, VB .NET SQL DateTime Parameter
$SqlCmd.Parameters.Add("@dateTimeValue", [System.Data.SqlDbType]::DateTime2).Value = $dateTime2ValueFigure: Good Example - PowerShell SQL DateTime Parameter
A view is a virtual table produced from executing a stored query on the database. Views don’t store any data as they retrieve the result set through a query. Users can interact with views similarly as they would with a normal table when retrieving data however limitations do exist when writing back to the result-set. Views can be used to simplify access to database result sets and provide more security options to administrators when granting access. More information can be found at CREATE VIEW (Transact-SQL)
Advantages:
1. Simplicity
- Multiple tables can be joined and simplified into a single virtual table.
- Complex calculations, groupings and filters can be hidden from the user so that the results appear as a simple dataset.
- Views can be used to transparently partition data such as having Sales2019 and Sales2020 but both views read from the underlying Sales table.
-
Duplication can be reduced in procedures and queries by using a common view.
2. Security
- Views can be used to provide a specific data set to a user while protecting the underlying tables.
-
Permission management of tables cannot be limited to a row or a column, but it can be implemented simply through views.
3. Flexibility
- Once the view structure is determined, you can shield the impact of changes in the table structure on users.
- Modifying the column name of the source table can be solved by modifying the view, without impacting end users.
- Aliases can be used on column names to make them more readable and descriptive.
- Adding columns to the source table has no impact on the view.
- The ability to soft-delete records by filtering them with an IsDeleted column.
Disadvantages:
1. Performance
-
Views can take longer to query than tables as they may contain complex functions or multi-table queries.
2. Dependencies
-
Views depend on the underlying tables for its data, so if the structure of the tables change it may break the view.
3. Update Restrictions
- Depending on the complexity of the view, you may not be able to modify the data through the view to the underlying base tables.
Modifying tables through views
In some cases, you can update the tables through a SQL view depending on its complexity.You can only update views with a single base table otherwise it may choose the incorrect base table to update.
INSERT INTO vwProductsNorthwind VALUES (@ItemName, @ItemCost); UPDATE vwProductsNorthwind SET Cost = @ItemCost WHERE Id = @ItemId; DELETE vwProductsNorthwind WHERE Id = @ItemId;**Figure: Example of an updatable view using a single base table**
More complex views, such as a multi-table view can be used after the where clause in another update statement.
-- Create the products by category view CREATE VIEW vwProductsByCategory AS SELECT p.Id, p.Name, p.Cost, p.OnSale, p.CategoryId FROM Products p JOIN Categories c ON p.CategoryId = c.Id -- Set all products from a particular category to be on sale UPDATE Products SET OnSale = @OnSale WHERE Id IN ( SELECT Id FROM vwProductsByCategory WHERE CategoryName = @CategoryName )Figure: Using a multi-table view after the when clause
Example Scenario
So your business has an employees table as shown below that has detailed information about their name, birthdate, home phone, address and photo. This information is suitable for the payroll department but what you want to display employees names and photos on the website for public viewing. Or what If you want contact information such as extension number and country to be available on the company intranet?
 Figure: Northwind traders employees table
You could create separate tables for each department, only supplying the required fields for each.
This would also need an additional system to sync between the tables to ensure the information was kept up to date.
Figure: Northwind traders employees table
You could create separate tables for each department, only supplying the required fields for each.
This would also need an additional system to sync between the tables to ensure the information was kept up to date.
Figure: Bad Example – Using tables and duplicating data
CREATE VIEW vwIntranetEmployees AS SELECT EmployeeID, LastName, FirstName, Title, TitleOfCourtesy, Country, Extension, Photo, PhotoPath FROM Employees; CREATE VIEW vwWebsiteProfiles AS SELECT EmployeeID, LastName, FirstName, Title, TitleOfCourtesy, Photo, PhotoPath FROM Employees;Figure: Good Example – Using views from the base table containing the source data
Creating views of the employee table allows you to update the data in one source location such as payroll and all other departments will see the changes. It prevents the problem of stale data and allows more control over access to the data.
There are lots of ways to retrieve data in SQL Server. In the old days, SQL Server Enterprise Manager was the way to go.
These days, it has been replaced by several other tools:
SQL Server Management Studio (SSMS)
Pros
✅ Mature tool with rich feature set, tailored specifically for SQL Server.
✅ Offers full-fledged management capabilities, from querying to administration tasks.
✅ Has built-in SQL Server specific features, like Profiler and SQL Server Agent.
Cons
❌ Windows-only software, can't be used on macOS or Linux.
❌ UI can be clunky and outdated compared to newer tools.
❌ May be overkill for simple query execution and data exploration.
Azure Data Studio
Pros
✅ Cross-platform (Windows, macOS, and Linux).
✅ Modern UI with customizable dashboard.
✅ Notebooks support (SQL and Python), enabling better documentation and interactive analysis.
Cons
❌ Less mature, so it might lack some advanced features compared to SSMS.
❌ Primarily designed for Azure SQL databases, though it supports on-premises SQL Server.
❌ Some users might find its user experience less intuitive than SSMS.
VS Code with the MSSQL extension
Pros
✅ Lightweight and cross-platform.
✅ Excellent if you're already using VS Code for other development tasks.
Cons
❌ Not as feature-rich as SSMS or Azure Data Studio when it comes to SQL Server specific tasks.

Figure: Bad Example - SQL Server Enterprise Manager is old and outdated 
Figure: Good Example - SSMS is feature rich 
Figure: Good Example - Azure Data Studio is lightweight and cross-platform 
Figure: Good Example - The VS Code MSSQL extension is embedded right in VS Code